fjoin()
本章节介绍fjoin()函数的用法。
A.fjoin ()
针对序表/排列做外键关联计算。
语法
A.fjoin(w:T,x:F,…;…)
备注:
针对序表/排列A的每一行计算w,再针对w计算x作为新字段F,结果返回A与F组成的新序表;
T为w的别名,可在x中引用;x是~时表示w;F若在A中已存在则重新赋值。
在w参数中可以通过外键来关联主子表。
参数:
|
A |
序表/排列。 |
|
w |
计算表达式,w除支持常规表达式写法以外,还支持以下两种用法: 1,K=w,赋值形式,K是A中的字段,w中可使用集算器函数。 2,(Ki=wi,…,w),组合使用Ki=wi,此处w是逻辑表达式,w中可引用Ki。 |
|
T |
w的别名,可省略。 |
|
x |
计算表达式,可省略。 |
|
F |
x的字段名,可省略。 |
返回值:
序表
选项:
|
@i |
w为null或false时删除当前行。 |
|
@m |
并行计算。 |
示例:
使用K=w表达式:
|
|
A |
|
|
1 |
=connect("demo").query("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES") |
|
|
2 |
=connect("demo").query("SELECT top 20 * FROM STATECAPITAL").keys(STATEID) |
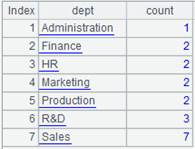
返回主键为STATEID的序表:
|
|
3 |
=A1.fjoin(STATEID=A2.find(STATEID)) |
使用k=w表达式,通过A1的外键STATEID来关联表A2,结果A1的外键赋值为A2的指引记录,外键对应不上时返回null:
|

使用@i选项:
|
|
A |
|
|
1 |
=connect("demo").query("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回序表:
|
|
2 |
=A1.fjoin@i(CID<5) |
使用@i选项,计算A1序表中CID小于5的记录,计算结果为null或false时删除整条记录: |
|
3 |
=connect("demo").query("SELECT top 20 * FROM STATECAPITAL").keys(STATEID) |
|
|
4 |
=A1.fjoin@i(STATEID=A3.find(STATEID)) |
使用@i选项,通过A1的外键STATEID来关联表A3,外键对应不上时删除整条记录:
|
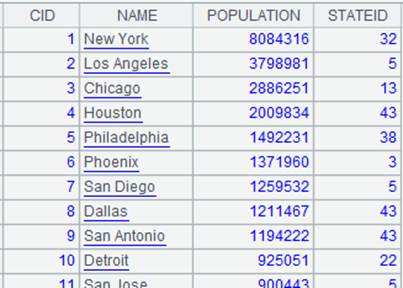


使用(Ki=wi,…,w)表达式:
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,DEPT from employee") |
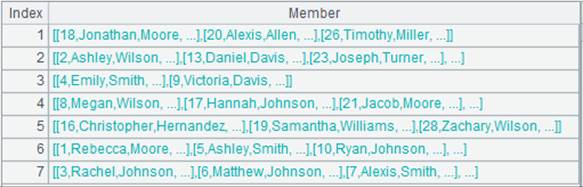
返回序表:
|
|
2 |
=6.new(~:ID,~*~:Num).keys(ID) |
生成以ID为键的序表:
|
|
3 |
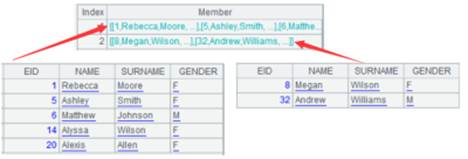
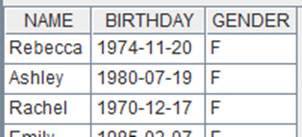
=create(name,gender).record(["Rebecca","F","Ashley","F","Matthew","M"]).keys(name) |
生成以name为键的序表:
|
|
4 |
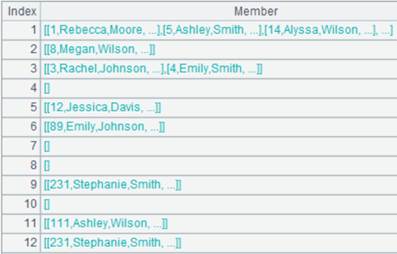
=A1.fjoin@i((EID=A2.find(EID),NAME=A3.find(NAME),EID!=null&&NAME!=null)) |
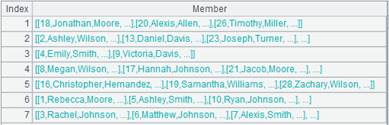
A1通过外键字段EID与A2关联,通过外键字段NAME与A3关联;将A1的外键EID切换为A2的指引记录,外键NAME切换为A3的指引记录,然后删除键值对应不上的记录:
|
|
5 |
=A1.fjoin@i((EID=A2.pfind(EID),NAME=A3.pfind(NAME),EID!=null&&NAME!=null)) |
A1通过外键字段EID与A2关联,通过外键字段NAME与A3关联;将A1的外键EID赋值为对应A2的键值所在的序号,外键NAME赋值为对应A3的键值所在的序号,然后删除对应不上的记录:
|
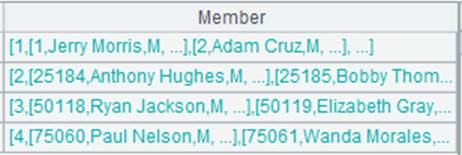

其他用法:
|
|
A |
|
|
1 |
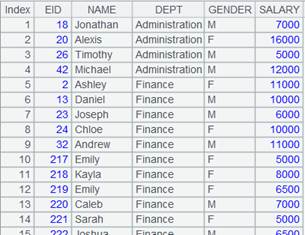
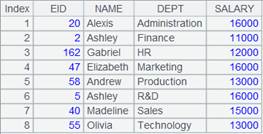
=demo.query("select EID,NAME,DEPT,GENDER,BIRTHDAY from employee") |
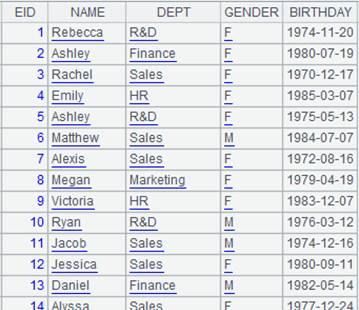
返回employee表数据:
|
|
2 |
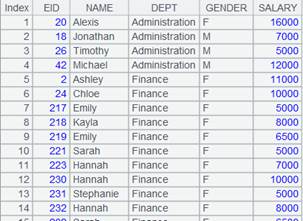
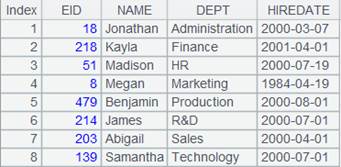
=A1.fjoin(age(BIRTHDAY):age,age>50:ifRetire) |
先计算A1表中每个员工的年龄,然后在计算年龄是否大于50岁,age为年龄计算结果的别名,最后将年龄是否大于50岁的计算结果作为新字段加到序表A1中,新字段名为ifRetire:
|
|
3 |
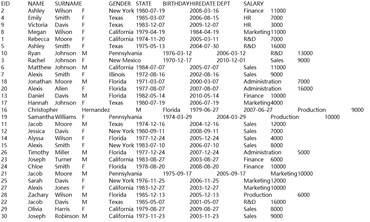
=A1.fjoin(age(BIRTHDAY),~:AGE) |
x中使用~表示w本身,即AGE列为age(BIRTHDAY)的计算结果:
|
cs.fjoin ()
描述:
语法
备注:
游标cs附加计算,对cs的每一行先计算w,再计算x,x作为新字段F的值拼接到cs中,返回原游标cs。
T为w的别名,可在x中引用;x是~时表示w;F若在cs中已存在则重新赋值。
在w参数中可以通过外键来关联主子表。
该函数属于延迟计算函数。
参数:
|
cs |
游标。 |
|
w |
计算表达式,w除支持常规表达式写法以外,还支持以下两种用法: 1,K=w,赋值形式,K是cs中的字段,w中可使用集算器函数。 2,(Ki=wi,…,w),组合使用Ki=wi,此处w是逻辑表达式,w中可引用Ki。 |
|
T |
w的别名,可省略。 |
|
x |
计算表达式,可省略。 |
|
F |
x的字段名,可省略。 |
返回值:
游标
选项:
|
@i |
w为null或false时删除当前行。 |
示例:
使用K=w表达式:
|
|
A |
|
|
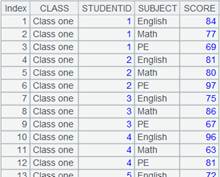
1 |
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标:
|
|
2 |
=connect("demo").query("SELECT top 20 * FROM STATECAPITAL").keys(STATEID) |
返回主键为STATEID的序表:
|
|
3 |
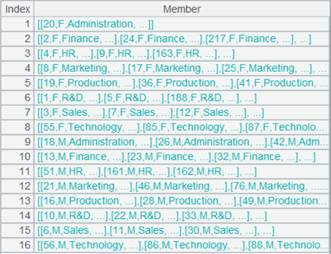
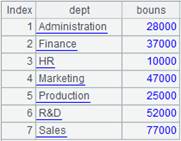
=A1.fjoin(STATEID=A2.find(STATEID)) |
游标A1附加计算,使用k=w表达式,通过A1的外键STATEID来关联表A2,将A1的外键赋值为A2的指引记录,外键对应不上时返回null,返回A1游标, A1游标执行计算后数据内容如下:
|
使用@i选项:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标,内容如下:
|
|
2 |
=connect("demo").query("SELECT top 20 * FROM STATECAPITAL").keys(STATEID) |
|
|
4 |
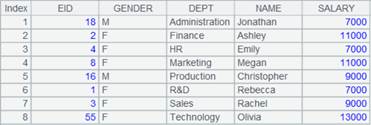
=A1.fjoin@i(STATEID=A2.find(STATEID)) |
游标A1附加计算,使用@i选项,通过A1的外键STATEID来关联表A2,外键对应不上时删除整条记录,返回A1游标, A1游标执行计算后数据内容如下:
|
使用(Ki=wi,…,w)表达式:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT from employee") |
返回游标,内容如下:
|
|
2 |
=6.new(~:ID,~*~:Num).keys(ID) |
生成以ID为键的序表:
|
|
3 |
=create(name,gender).record(["Rebecca","F","Ashley","F","Matthew","M"]).keys(name) |
生成以name为键的序表:
|
|
4 |
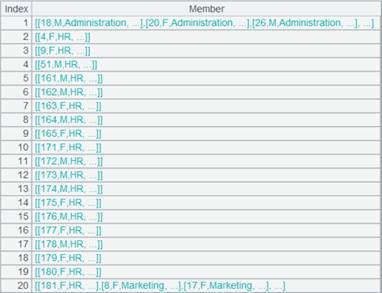
=A1.fjoin@i((EID=A2.find(EID),NAME=A3.find(NAME),EID!=null&&NAME!=null)) |
游标A1附加计算,A1通过外键字段EID与A2关联,通过外键字段NAME与A3关联;将A1的外键EID切换为A2的指引记录,外键NAME切换为A3的指引记录,然后删除键值对应不上的记录,返回A1游标, A1游标执行计算后数据内容如下:
|
|
5 |
=demo.cursor("select EID,NAME,DEPT from employee") |
同A1。 |
|
6 |
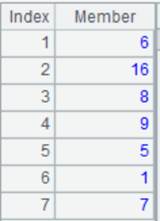
=A5.fjoin@i((EID=A2.pfind(EID),NAME=A3.pfind(NAME),EID!=null&&NAME!=null)) |
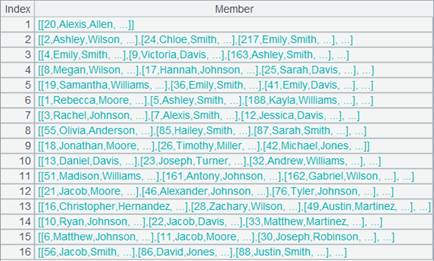
游标A5附加计算,A5通过外键字段EID与A2关联,通过外键字段NAME与A3关联;将A5的外键EID赋值为对应A2的键值所在的序号,外键NAME赋值为对应A3的键值所在的序号,然后删除对应不上的记录,返回A5游标, A5游标执行计算后数据内容如下:。
|

其他用法:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER,BIRTHDAY from employee") |
返回游标,employee表数据如下:
|
|
2 |
=A1.fjoin(age(BIRTHDAY):age,age>50:ifRetire) |
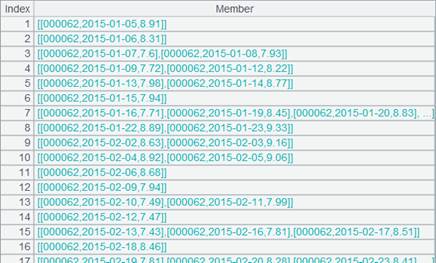
游标A1附加计算,先计算A1表中每个员工的年龄,然后在计算年龄是否大于50岁,age为年龄计算结果的别名,最后将年龄是否大于50岁的计算结果作为新字段加到游标中,新字段名为ifRetire,返回A1游标, A1游标执行计算后数据内容如下:
|
|
3 |
=A1.fjoin(age(BIRTHDAY),~:AGE) |
游标A1附加计算,x中使用~表示w本身,即AGE列为age(BIRTHDAY)的计算结果,返回A1游标, A1游标执行计算后数据内容如下:
|

|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER,BIRTHDAY from employee") |
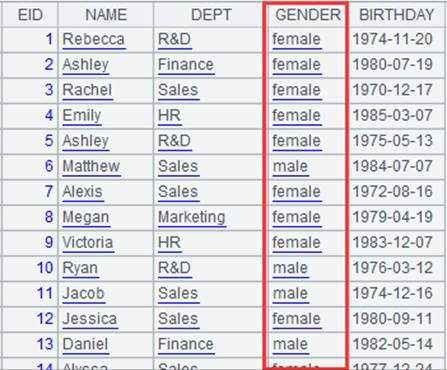
返回游标,数据内容如下:
|
|
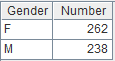
2 |
游标A1附加计算,w使用赋值形式,当GENDER的值为F时返回为female,否则返回为male, 由于w的别名GENDER在序列中已存在,所以不生成新的列而是对A1中的GENDER重新赋值,返回A1游标, A1游标执行计算后数据内容如下:
|
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标,内容如下:
|
|
2 |
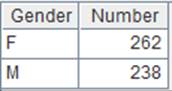
=A1.fjoin@i(CID<5) |
游标A1附加计算,使用@i选项,计算A1中CID小于5的记录,计算结果为null或false时删除整条记录,返回A1游标, A1游标执行计算后数据内容如下: |
ch.fjoin ()
描述:
管道中附加外键关联计算动作后返回原管道。
ch.fjoin(w:T,x:F,…;…)
备注:
管道ch附加计算,对ch的每一行先计算w,再计算x,x作为新字段F的值拼接到ch中,返回原管道ch;
T为w的别名,可在x中引用;x是~时表示w;F若在ch中已存在则重新赋值。
在w参数中可以通过外键来关联主子表。
该函数属于附加计算动作。
参数:
|
ch |
管道。 |
|
w |
计算表达式,w除支持常规表达式写法以外,还支持以下两种用法: 1,K=w,赋值形式,K是ch中的字段,w中可使用集算器函数。 2,(Ki=wi,…,w),组合使用Ki=wi,此处w是逻辑表达式,w中可引用Ki。 |
|
T |
w的别名,可省略。 |
|
x |
计算表达式,可省略。 |
|
F |
x的字段名,可省略。 |
返回值:
管道
选项:
|
@i |
w为null或false时删除当前行。 |
示例:
使用K=w表达式:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标,内容如下:
|
|
2 |
=channel() |
创建管道。 |
|
3 |
=A1.push(A2) |
将A1的数据推送到管道,此时数据不会立即被推送到管道。 |
|
4 |
=connect("demo").query("SELECT top 20 * FROM STATECAPITAL").keys(STATEID) |
返回主键为STATEID的序表:
|
|
5 |
=A2.fjoin(STATEID=A4.find(STATEID)) |
管道A2附加计算,使用k=w表达式,通过A2管道的外键STATEID来关联表A4,将A2的外键赋值为A4的指引记录,外键对应不上时返回null,返回原管道。 |
|
6 |
=A2.fetch() |
A2管道执行结果集函数,保留管道当前数据。 |
|
7 |
=A1.fetch() |
A1游标执行取数动作,此时数据才会被推送到管道,然后管道执行计算并记录结果。 |
|
8 |
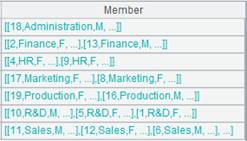
=A2.result() |
获取管道A2的计算结果:
|

使用@i选项:
|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标,内容如下:
|
|
2 |
=channel() |
创建管道。 |
|
3 |
=A1.push(A2) |
将A1的数据推送到管道,此时数据不会立即被推送到管道。 |
|
4 |
=connect("demo").query("SELECT top 20 * FROM STATECAPITAL").keys(STATEID) |
返回主键为STATEID的序表:
|
|
5 |
=A2.fjoin@i(STATEID=A4.find(STATEID)) |
管道A2附加计算,使用@i选项,通过A1的外键STATEID来关联表A2,外键对应不上时删除整条记录,A8中可查看计算结果。 |
|
6 |
=A2.fetch() |
A2管道执行结果集函数,返回原管道。 |
|
7 |
=A1.fetch() |
A1游标执行取数动作,此时数据才会被推送到管道,然后管道执行计算并记录结果。 |
|
8 |
=A2.result() |
获取管道A2的计算结果:
|
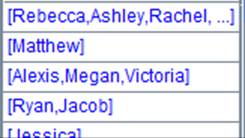
使用(Ki=wi,…,w)表达式:
|
|
A |
|
|
1 |
=demo.cursor("select EID,NAME,DEPT,GENDER,BIRTHDAY from employee") |
返回游标,内容如下:
|
|
2 |
=channel() |
创建管道。 |
|
3 |
=channel() |
创建管道。 |
|
4 |
=A1.push(A2,A3) |
将A1的数据推送到管道A2、A3,此时数据不会立即被推送到管道。 |
|
5 |
=6.new(~:ID,~*~:Num).keys(ID) |
生成以ID为键的序表:
|
|
6 |
=create(name,gender).record(["Rebecca","F","Ashley","F","Matthew","M"]).keys(name) |
生成以name为键的序表:
|
|
7 |
=A2.fjoin@i((EID=A5.find(EID),NAME=A6.find(NAME),EID!=null&&NAME!=null)) |
管道A2附加计算, A2通过外键字段EID与A5关联,通过外键字段NAME与A6关联;将A2的外键EID切换为A5的指引记录,外键NAME切换为A6的指引记录,然后删除键值对应不上的记录,返回原管道。 |
|
8 |
=A2.fetch() |
A2管道执行结果集函数,保留管道当前数据 |
|
9 |
=A3.fjoin@i((EID=A5.pfind(EID),NAME=A6.pfind(NAME),EID!=null&&NAME!=null)) |
管道A3附加计算, A3通过外键字段EID与A5关联,通过外键字段NAME与A6关联;将A3的外键EID赋值为对应A5的键值所在的序号,外键NAME赋值为对应A6的键值所在的序号,然后删除对应不上的记录,在A13中可查看计算结果。 |
|
10 |
=A3.fetch() |
A3管道执行结果集函数,保留管道当前数据。 |
|
11 |
=A1.fetch() |
A1游标执行取数动作,此时数据才会被推送到管道,然后管道执行计算并记录结果。 |
|
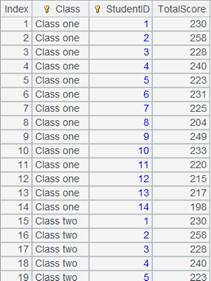
12 |
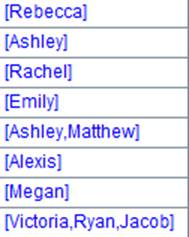
获取管道A2的计算结果:
|
|
|
13 |
=A3.result() |
获取管道A3的计算结果:
|

其他用法:
|
|
A |
|
|
1 |
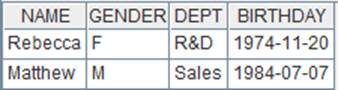
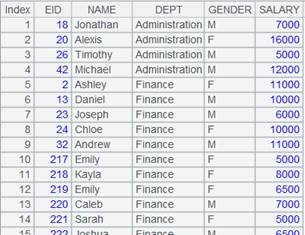
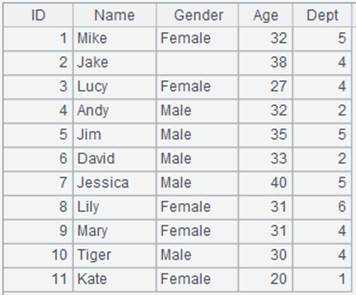
=demo.cursor("select EID,NAME,DEPT,GENDER,BIRTHDAY from employee") |
返回游标,employee表数据如下:
|
|
2 |
=channel() |
创建管道。 |
|
3 |
=channel() |
创建管道。 |
|
4 |
=A1.push(A2,A3) |
将A1的数据推送到管道,此时数据不会立即被推送到管道。 |
|
5 |
=A2.fjoin(age(BIRTHDAY):age,age>50:ifRetire) |
管道A2附加计算,先计算表中每个员工的年龄,然后再计算年龄是否大于50岁,age为年龄计算结果的别名,最后将年龄是否大于50岁的计算结果作为新字段合并到管道A2中,新字段名为ifRetire,返回原管道A2。 |
|
6 |
=A2.fetch() |
A2管道执行结果集函数,保留管道当前数据。 |
|
7 |
=A3.fjoin(age(BIRTHDAY),~:AGE) |
管道A3附加计算,x中使用~表示w本身,即AGE列为age(BIRTHDAY)的计算结果,返回原管道A3。 |
|
8 |
=A3.fetch() |
A3管道执行结果集函数,保留管道当前数据。 |
|
9 |
=A1.fetch() |
A1游标执行取数动作,此时数据才会被推送到管道,然后管道执行计算并记录结果。 |
|
10 |
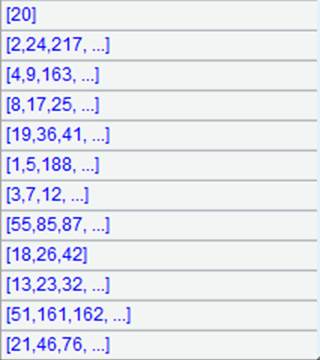
=A2.result() |
获取管道A2的计算结果:
|
|
11 |
=A3.result() |
获取管道A3的计算结果:
|

|
|
A |
|
|
1 |
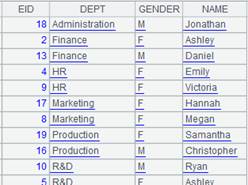
=demo.cursor("select EID,NAME,DEPT,GENDER,BIRTHDAY from employee") |
返回游标,数据内容如下:
|
|
2 |
=channel() |
创建管道。 |
|
3 |
=A1.push(A2) |
将A1的数据推送到管道,此时数据不会立即被推送到管道。 |
|
4 |
=A2.fjoin(if(GENDER=="F","female","male"):GENDER,GENDER) |
管道A2附加计算,w使用赋值形式,当GENDER的值为“F”时返回为female,否则返回为male,由于w的别名GENDER在管道中已存在,所以不生成新的列而是对管道中的GENDER重新赋值,返回原管道。 |
|
5 |
=A2.fetch() |
A2管道执行结果集函数,保留管道当前数据。 |
|
6 |
=A1.fetch() |
A1游标执行取数动作,此时数据才会被推送到管道,然后管道执行计算并记录结果。 |
|
7 |
=A2.result() |
获取管道A2的计算结果:
|

|
|
A |
|
|
1 |
=connect("demo").cursor("SELECT top 20 CID,NAME,POPULATION,STATEID FROM CITIES") |
返回游标,内容如下:
|
|
2 |
=channel() |
创建管道。 |
|
3 |
=A1.push(A2) |
将A1的数据推送到管道,此时数据不会立即被推送到管道。 |
|
4 |
=A2.fjoin@i(CID<5) |
管道A2附加计算,使用@i选项,计算管道中CID小于5的记录,计算结果为null或false时删除整条记录,返回原管道。 |
|
5 |
=A2.fetch() |
A2管道执行结果集函数,保留管道当前数据。 |
|
6 |
=A1.fetch() |
A1游标执行取数动作,此时数据才会被推送到管道,然后管道执行计算并记录结果。 |
|
7 |
=A2.result() |
获取管道A2的计算结果:
|