
f.cursor()
描述:
根据文件创建游标。
语法:
|
f.cursor() |
|
f.cursor(Fi:type,…;k:n,s) |
备注:
根据文件f创建游标并返回,数据扫描完将自动关闭游标。
参数:
|
f |
文件对象,仅支持文本文件对象。 |
|
Fi |
读出的字段,缺省读出所有,用#时表示用序号定位。 |
|
type |
字段类型,包括:bool、int、long、float、decimal、string、date、time和datetime,缺省使用第一行数据类型。 |
|
s |
自选分隔符,缺省默认分隔符是tab。省略参数s时,s前边的逗号可以省略。 |
|
k |
分段号。 |
|
n |
总段数。k和n都省略时表示读全文件。 |
选项:
|
@t |
f中第一行记录作为字段名,不使用本选项时默认使用_1,_2,…作为字段名。 |
|
@b |
读取由export方式写出的二进制文件,支持参数Fi、k和n,不支持参数type和s,忽略选项@t@s@i@q@a@n@k@p@f@l@m@c@o@d@v@r。记录数少的文件在分段读取时可能会有空段。 |
|
@e |
Fi在文件中不存在时将生成null,缺省将报错。 |
|
@x |
关闭时自动删除文件,使用该选项返回的游标不能回转。 |
|
@s |
不拆分字段,读成游标,游标内容为单字段串构成的序表,忽略参数。 |
|
@i |
结果集只有1列时返回的游标内容为序列。 |
|
@q |
剥离数据项两端引号,包括标题,处理转义;中间的引号不作处理。 |
|
@c |
s缺省时用逗号分隔。 |
|
@m |
f.cursor@m(Fi:type,…;n,s),返回成多路游标,此处n表示路数,缺省使用设计器中设置的多路游标缺省路数值作为路数,第三方应用程序中集成使用时,缺省路数为raqsoftConfig.xml文件中配置的cursorParallelNum的值。 |
|
@o |
用引号作为转义符。 |
|
@k |
保留数据项两端的空白符,缺省将自动删除两端空白符。 |
|
@d |
行内有数据不匹配类型和格式时删除该行,此时会按type检查类型;@p@q时括号和引号不匹配时也删除该行。 |
|
@n |
列数和第一行不匹配也作为错误处理,不匹配的记录行将被抛弃。 |
|
@v |
@d@n检查出错时抛出违例,中断程序,输出出错行的内容。 |
|
@w |
把每行读成序列,结果为序列的序列构成的游标,列名也算作一行。 |
|
@a |
将单引号作为引号处理,缺省不处理,可与@q@p组合使用。 |
|
@p |
解析时处理括号和引号匹配,括号内分隔符不算,同时引号外转义也处理。 |
|
@f |
不做任何解析,简单用分隔符拆成串。 |
|
@l |
允许续行,行尾是转义字符\ 。 |
|
@y |
使用定长方式解析数据,fmt解释为字段的宽度;type为日期时间类型数据时,用fmt计算出宽度。 与@t选项互斥,Fi解释为结果集字段名,省略表示跳过该字段,不可改变原文件中字段次序。 有@e时,未写fmt的字段认为是加入的空字段,否则报错。 |
游标/多路游标
示例:
|
|
A |
B |
C |
|
|
1 |
=file("D://Student.txt").cursor@tx() |
|
|
返回取数游标,将第一行记录作为字段名,并且关闭游标时自动删除文件。 |
|
2 |
=create(CLASS,STUDENTID,SUBJECT,SCORE) |
|
|
构造新序表。 |
|
3 |
for |
|
|
|
|
4 |
|
if A3==1 |
=A1.skip(5) |
当循环序号为1时,连跳5行。 |
|
5 |
|
=A1.fetch(3) |
|
从游标A1取数,每次取3条。 |
|
6 |
|
if B5==null |
|
当B5为空时跳出循环。 |
|
7 |
|
|
break |
|
|
8 |
|
else |
|
|
|
9 |
|
|
>A2.insert(0:B5, CLASS,STUDENTID,SUBJECT,SCORE) |
把B5记录插入到A2中。 |
|
10 |
=file("D://Department.txt").cursor@t(Dept,Manager;,"/") |
|
=A10.fetch() |
Department.txt文件内容:
Department.txt内容以斜杠分隔,按照指定字段Dept和Manager读出:
|
|
11 |
=file("D://Department5.txt").cursor@t(;1:2) |
|
=A11.fetch() |
省略选出字段和分隔符,将游标分成2段,读取第1段的数据。 |
|
12 |
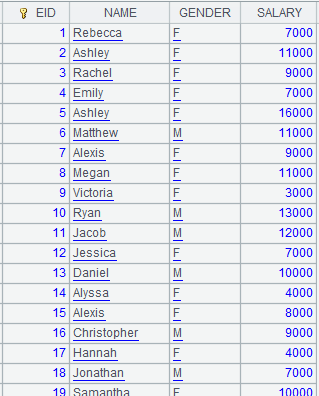
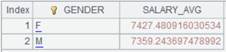
=file("D://EMPLOYEE.btx").cursor@b(GENDER;1:2) |
|
=A12.fetch() |
读取集文件EMPLOYEE.btx中的字段GENDER。 |
|
13 |
=file("D://EMPLOYEE1.btx").cursor@b(;1:2) |
|
=A13.fetch() |
读取f.export@b()导出的二进制文件EMPLOYEE1.btx,并且将文件内容分成2份,取第1份。 |
|
14 |
=file("D://Department.txt").cursor@ts() |
|
=A14.fetch() |
不拆分字段,游标内容为单字段串构成的序表:
|
|
15 |
=file("D://StuName.txt").cursor@i() |
|
=A15.fetch() |
StuName.txt为单字段文件,游标内容为序列。 |
|
16 |
=file("D://EMPLOYEE1.txt").cursor@tc() |
|
=A16.fetch() |
|
|
17 |
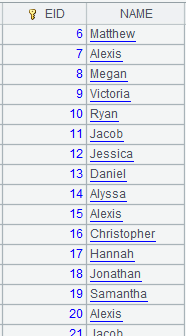
=file("D://Department3.txt").cursor@e(EID) |
|
=A17.fetch() |
Department3.txt文件中没有字段EID,结果返回空,若不使用@e选项,则会报错,报错信息为:EID: field is not found。 |
|
18 |
=file("D://Department2.txt").cursor@tq(;,"|") |
|
=A18.fetch() |
Department2.txt中内容如下:
B19结果如下:
|
|
19 |
=file("D://Department.txt").cursor@tm(DEPT:string,MANAGER:int;3,"/") |
|
|
将游标分为3段,A19返回成多路游标。 |
|
20 |
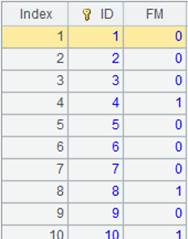
=file("D://Sale1.txt").cursor(#1,#3) |
|
=A20.fetch() |
Sale1.txt内容如下:
B20的结果如下:
|
|
21 |
=file("D:/Dep3.txt").cursor@cqo() |
|
=A21.fetch() |
使用@o选项,串中两个引号表示一个引号,返回结果:
|
|
22 |
=file("D:/Dep1.txt").cursor@k() |
|
=A22.fetch() |
保留数据项两端的空白符。 |
|
23 |
=file("D:/Department1.txt").cursor@t(id:int,name;,"|") |
|
=A23.fetch() |
返回Department1.txt中的字段id与name:
|
|
24 |
=file("D:/Department1.txt").cursor@td(id:int,name;,"|") |
|
=A24.fetch() |
行内有数据不匹配类型时删除该行,对比B23的结果,可以看到id为a的行被删除。 |
|
25 |
=file("D:/Department1.txt").cursor@tv(id:int,name;,"|") |
|
=A25.fetch() |
检查类型匹配且出错时抛出违例,中断程序,输出出错行的内容,对比B23的结果,可以看到id为a的行类型不匹配。 |
|
26 |
=file("D:/Dep2.txt").cursor@tdn(id:int,name,surname;,"|") |
|
=A26.fetch() |
Dep2.txt文件内容:
第6、8行列数与第一行不匹配,故忽略:
|
|
27 |
=file("D:/Desktop/DemoData/txt/City.txt").cursor@w() |
|
=A27.fetch() |
使用@w选项,将每行读成序列的序列:
|
|
28 |
=file("D://t1.txt").cursor@c() |
|
=A28.fetch() |
t1.txt文件内容:
使用@c选项,分隔符缺省使用逗号,返回结果:
|
|
29 |
=file("D://t1.txt").cursor@cp() |
|
=A29.fetch() |
使用@p选项,解析时处理括号和引号匹配:
|
|
30 |
=file("D://t1.txt").cursor@cpa() |
|
=A30.fetch() |
使用@a选项,将单引号作为引号处理:
|
|
31 |
=file("D://t2.txt").cursor@l() |
|
=A31.fetch() |
t2.txt内容如下:
使用@l选项,行尾为转义符\时允许续行:
|
|
32 |
=file("D://t3.txt").cursor@f() |
|
=A32.fetch() |
使用@f选项,直接用分隔符拆成串:
|
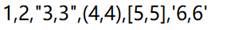


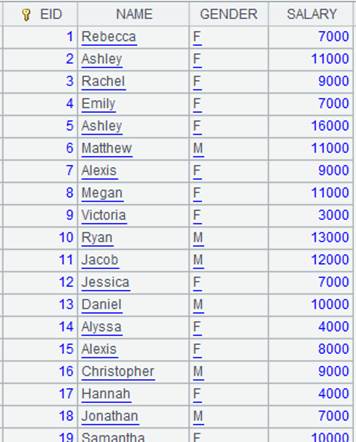
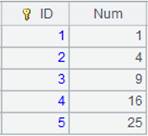

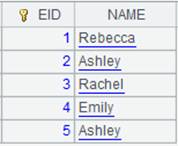

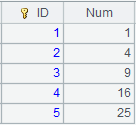
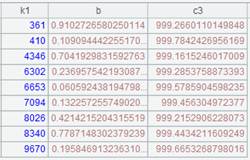

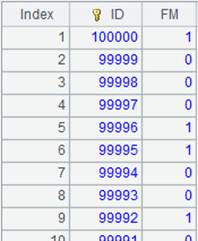
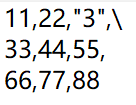
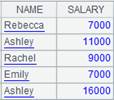
使用定长方式解析数据:
|
|
A |
|
|
1 |
=file("um.txt") |
|
|
2 |
=A1.cursor().fetch() |
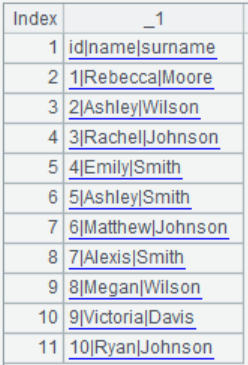
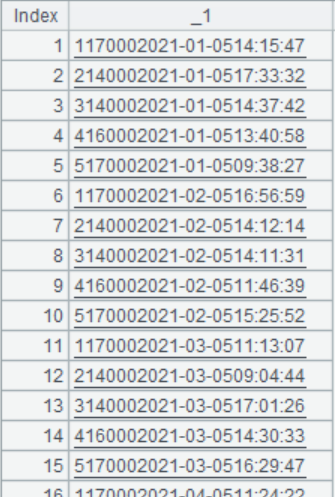
根据文件um.txt创建游标,并读取游标中的数据,返回内容如下:
|
|
3 |
=A1.cursor@y(UID:int:1,Amount:int:5,Udate:string:18).fetch() |
使用@y选项,用定长方式解析数据,第一列数据宽度为1,数据类型为int,列名为UID;第二列数据宽度为5,数据类型为int,列名为Amount;第二列数据宽度为18,数据类型为string,列名为Udate,返回结果如下:
|
|
4 |
=A1.cursor@y(UID:int:1,Amount:int:5,Udate:datetime:"yyyy-MM-ddHH:mm:ss").fetch() |
第三列为日期时间类型,可以根据时间日期格式计算出列宽度,返回结果如下:
|
|
5 |
=A1.cursor@ye(UID:int:1,UName::,Amount:int:5,Udate:string:18).fetch() |
有@e时,第二列中fmt参数为空认为是加入的空字段,返回结果如下:
|

相关概念: