export()
本章介绍export()函数的多种用法。
A.export()
将序列转成字符串。
语法:
A.export(x:F,…;s)
备注:
将序表/排列/序列A中的每条记录,选出字段x并用自选分隔符s隔开,结果以字符串形式返回,结果字符串中的字段名为F。
当省略参数x时,输出所有字段,A是序列时生成无名称的单列串,A成员是序列时则再拼上分隔符。排号按作整数存。
当省略参数x:F时,若A是包含记录的序列,则记录必须是相同数据结构。
当A中成员为序列时,返回json串,为排号键则写成十六进制串。
注意,返回的字符串中,记录间用换行符隔开,字段间用自选分隔符隔开,缺省为tab键隔开。
选项:
|
@t |
列名作为第一条记录写在字符串开头。 |
|
@c |
s缺省时用逗号分隔。 |
|
@w |
换行符使用windows风格,即用\r\n,缺省按照操作系统规定。 |
|
@q |
导出的文本字段值和标题带有引号。 |
|
@o |
使用Excel标准转义,串中双个引号表示一个引号,其它字符不转义,该选项需要与@q配合使用。 |
参数:
|
A |
需要输出的序表/排列/序列。 |
|
x |
输出的字段,省略则输出A中所有字段。 |
|
F |
字串中的结果字段名,省略则使用原字段名。 |
|
s |
字段间自选分隔符,缺省分隔符是tab 。 |
返回值:
字符串
示例:
|
|
A |
|
|
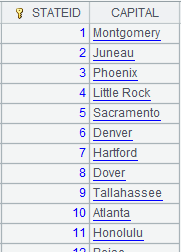
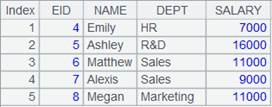
1 |
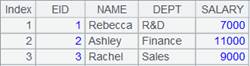
=demo.query("select EID,NAME from EMPLOYEE") |
|
|
2 |
=A1.export() |
省略x、F和s参数。 |
|
3 |
=A1.export(;"|") |
指定分隔符为“|” |
|
4 |
=A1.export@t(EID:id,NAME:name;",") |
指定选出字段和分隔符,并且将列名作为第一条记录写在字符串开头。 |
|
5 |
[1,23,34,45] |
序列。 |
|
6 |
=A5.export() |
|
|
7 |
=A1.export@c() |
使用@c选项,无s参数时默认用逗号分隔。 |
|
8 |
=A1.export@w() |
换行符使用windows风格,即用\r\n。 |
|
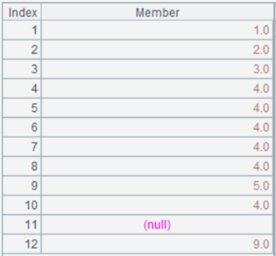
9 |
=["12\r34","aa\nbb"] |
|
|
10 |
=A9.export() |
|
|
11 |
=A9.export@q() |
使用@q选项,导出的内容带有引号。 |
|
12 |
<xml><row><DEPTID>1</DEPTID><DEPTNAME>sale</DEPTNAME> <FATHER>12</FATHER></row><row><DEPTID>10</DEPTID> <DEPTNAME>create</DEPTNAME><FATHER>12</FATHER></row></xml> |
|
|
13 |
=xml(A12) |
返回由序表组成的序列:
展开:
再展开:
|
|
14 |
=A13.export() |
返回json串:
|
|
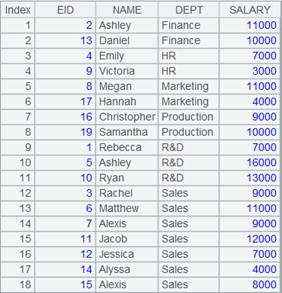
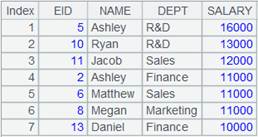
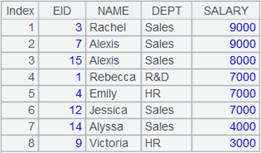
15 |
=file("D://t4.txt").import@coq() |
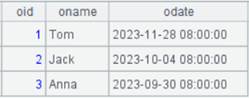
t4.txt内容如下:
A15结果:
|
|
16 |
=A15.export@coq() |
使用@o选项,串中两个引号表示一个引号:
|

相关概念:
f.export(A/cs ,x:F,…;s)
描述:
备注:
将A/cs计算表达式x后以文本形式写入到文件f中。
参数x省略则写入所有字段,当字段取值为引用记录,则写入记录的主键,F为x的结果字段名。
当文件f不存在时,自动创建(但不能自动创建路径目录),创建的文件缺省为文本格式。
当A是序列且x参数省略时,以无字段名的单列文本形式写入文件f。
当A中成员为序列时,缺省写成json串。
当A中存在排号类型的字段时,此字段值以十六进制串形式写入。二进制输出时则使用原数据类型。
A中不可输出的字段(比如图片)不能写入文件f。
注意,txt文件的格式:记录间用回车符隔开,字段间用自选分隔符隔开,缺省为tab键隔开。
选项:
|
@t |
将字段信息(标题)作为第一行写入文件。 |
|
@a |
追加写入;追加的内容要与原文件内容结构相同,否则报错;文件已有内容时忽略@t;缺省覆盖原文件。 |
|
@b |
写成二进制文件,速度更快。忽略@t;小文件不分段,足够大则重写分段。 @b时,参数s为A的字段或字段表达式,有参数s时认为A对s有序,仅在s变化时才分段;追加写时新数据的s值必须是不同的。 |
|
@c |
s缺省时用逗号分隔。 |
|
@w |
换行符使用windows风格,即用\r\n,缺省操作系统规定。 同时使用@b时,将序列的序列写成结构化数据,第一行作为字段名。 |
|
@q |
导出的文本字段值和标题都带有引号。 |
|
@o |
使用Excel标准转义,串中双个引号表示一个引号,其它字符不转义。 |
参数:
|
f |
文件对象。支持txt、csv、btx等格式的数据文件。导出Excel文件时使用f.xlsexport()。 |
|
A/cs |
序列/游标,A成员是序列时,则再拼上分隔符写出。 |
|
x |
需要输出的字段,省略则导出A/cs中所有可文本化字段,用#时表示用序号定位。 |
|
F |
结果字段名,省略则使用x。 |
|
s |
对于文本文件为自选分隔符,缺省默认分隔符是tab。 |
示例:
将序表写出到txt文件:
|
|
A |
|
|
1 |
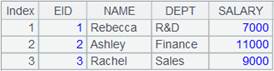
=demo.query("select * from DEPARTMENT") |
|
|
2 |
=file("Dep.txt").export(A1;"|") |
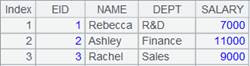
将A1序表中所有字段写入到文件中,|为分隔符,生成文件内容如下:
|
使用@t选项,将第一行作为标题写入:
|
|
A |
|
|
1 |
=demo.query("select * from DEPARTMENT") |
|
|
2 |
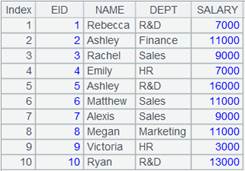
=file("Dep.txt").export@t(A1)
|
生成文件内容如下:
|
使用@a选项,追加写入:
|
|
A |
|
|
1 |
=demo.query("select * from DEPARTMENT") |
|
|
2 |
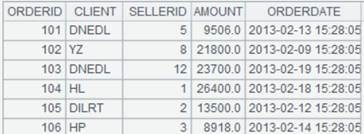
=file("Dep.txt").export@a(A1) |
在原文件内容后追加A1中的内容:
|

导出指定字段:
|
|
A |
|
|
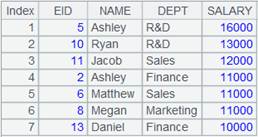
1 |
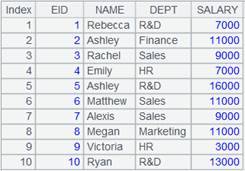
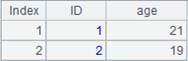
=demo.cursor("select EID,NAME,BIRTHDAY,SALARY from EMPLOYEE") |
|
|
2 |
=file("emp.txt").export@t(A1,NAME,age(BIRTHDAY):Age) |
导出A1游标中的NAME、BIRTHDAY字段,BIRTHDAY计算表达式后结果字段名设为Age:
|
|
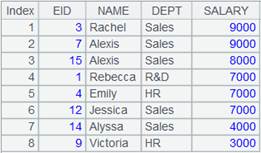
3 |
=file("emp2.txt").export@t(A1,#1,#2) |
使用#1,#2表示A1中的第1、第2个字段:
|


使用@b选项,写出到集文件:
|
|
A |
|
|
1 |
=demo.query("select * from DEPARTMENT") |
|
|
2 |
=file("Dep.btx").export@b(A1) |
写出的集文件默认带有标题:
|
使用@b选项,写出分段集文件:
|
|
A |
|
|
1 |
=10000.new(~:id,rand(10):xb).sort(xb) |
生成对xb字段有序的序表。 |
|
2 |
=file("stest.btx").export@b(A1;xb) |
写出根据xb分段的集文件,在xb有变化时分段。 |
使用@wb选项,将序列的序列写成结构化数据:
|
|
A |
|
|
1 |
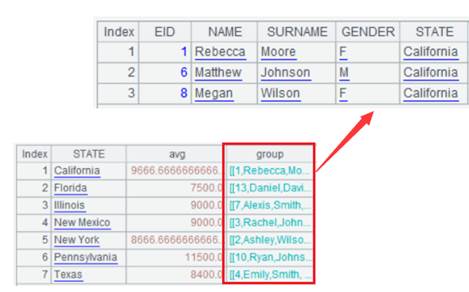
=demo.query("select EID,NAME,DEPT,SALARY from EMPLOYEE") |
返回序表:
|
|
2 |
=A1.array() |
返回序列的序列:
|
|
3 |
=file("emp_b.btx").export@b(A2) |
将A2写出到集文件emp_b.btx,查看文件内容如下:
|
|
4 |
=file("emp_wb.btx").export@wb(A2) |
使用@wb选项,将A2序列的序列以结构化数据的形式写入到集文件emp_wb.btx,查看文件内容如下:
|
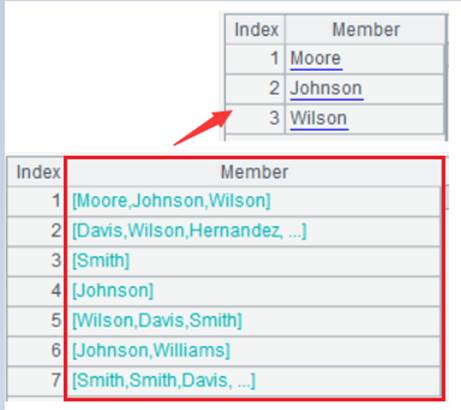
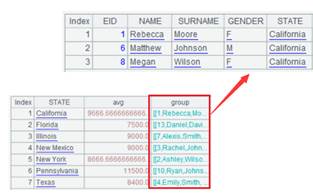
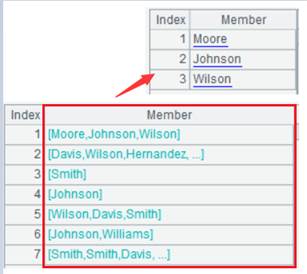
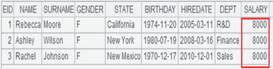
写出序列且省略x参数时:
|
|
A |
|
|
1 |
[a,s,d,f] |
|
|
2 |
=file("myfile.txt").export(A1) |
生成无字段名单列文件:
|

序表的字段值为引用记录时:
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,DEPT from EMPLOYEE order by GENDER") |
|
|
2 |
=demo.query("select DEPT,MANAGER from DEPARTMENT").keys(MANAGER) |
|
|
3 |
=A1.switch(DEPT,A2:DEPT) |
DEPT字段值为指引记录:
|
|
4 |
=file("empswtich.txt").export@t(A3) |
导出文件结果如下:
|
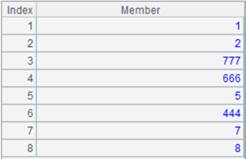
写入json串:
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,DEPT,SALARY from EMPLOYEE") |
|
|
2 |
=A1.group(DEPT).new(~:DEPT) |
返回序列,成员为序表:
|
|
3 |
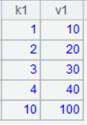
=file("empj.txt").export(A2) |
文件中写入json串:
|

使用@q选项,写出的文本字段值和标题带有引号:
|
|
A |
|
|
1 |
=demo.query("select * from DEPARTMENT") |
|
|
2 |
=file("Dep.txt").export@qt(A1,#1) |
|

使用@o选项,串中两个引号表示一个引号:
|
|
A |
|
|
1 |
f1,f2,f3 2,"dd""ff",3 |
|
|
2 |
=A1.import@coq() |
|
|
3 |
=file("o.txt").export@coq(A2) |
使用@o选项,串中两个引号表示一个引号,写出的t5.txt内容如下:
|