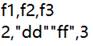derive()
本章介绍derive()的多种用法。
A.derive()
描述:
为序表/排列添加字段。
语法:
A.derive(xi :Fi,…)
备注:
给序表/排列A增加Fi,…字段,对A的每条记录遍历,给每个Fi赋值为xi,返回由原字段与新增字段Fi组成的新序表。
参数:
|
Fi |
字段名,此时Fi不能与A中原有字段同名。 |
|
xi |
表达式,计算结果作为字段值。 |
|
A |
序表/排列。 |
选项:
|
@m |
数据量大的复杂运算中,并行计算提升性能,计算次序不确定。 |
|
@i |
有xi且计算结果为空时不生成该行记录。 |
|
@x(…;n) |
抄原字段时,将字段取值为记录的字段展开,n为层数,缺省为2。 |
|
@o |
A是序表时,增加的列加到原序表上,不产生新的。 |
|
@z |
逆向计算,仅适用于非纯序列。 |
返回值:
序表
示例:
|
|
A |
|
|
1 |
=demo.query("select NAME,BIRTHDAY,HIREDATE from EMPLOYEE") |
|
|
2 |
=A1.derive(interval@y(BIRTHDAY, HIREDATE):EntryAge,age(HIREDATE):WorkAge) |
|
|
3 |
=A1.derive@m(age(HIREDATE):WorkAge) |
数据量大时提升性能。 |
|
4 |
=file("D:\\txt_files\\data1.txt").import@t() |
data1.txt中内容如下:
|
|
5 |
=A4.derive@i(SCORE:score_not_null) |
SCORE计算结果为空时,对应的该条记录不生成。
|
|
6 |
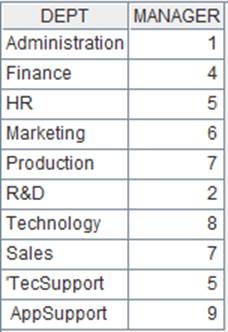
=demo.query("select * from DEPARTMENT") |
|
|
7 |
=demo.query("select NAME,GENDER,DEPT,SALARY from EMPLOYEE") |
|
|
8 |
>A7.switch(DEPT,A6:DEPT) |
将A7表中的DEPT字段值切换为记录。 |
|
9 |
=A7.derive(SALARY*5:BONUS) |
添加字段BONUS:
|
|
10 |
=A7.derive@x(SALARY*5:BONUS) |
使用@x选项,将原字段取值为记录的字段展开,默认展开两层。
|
|
11 |
=demo.query("select NAME,BIRTHDAY,HIREDATE from EMPLOYEE") |
返回序表。 |
|
12 |
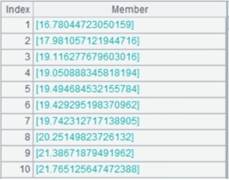
=A11.derive@o(age(HIREDATE):WorkAge) |
增加的列直接加到原序表上,不产生新的,此时A11与A12返回结果相同,结果如下:
|
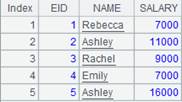
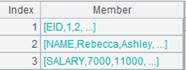
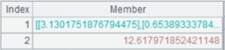


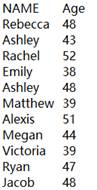

逆向计算:
|
|
A |
|
|
1 |
=demo.query("select * from SCORES ") |
返回序表:
|
|
2 |
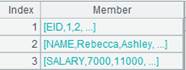
=A1.derive(cum(SCORE;CLASS,STUDENTID):F1) |
增加字段F1,循环函数中迭代运算,对有相同CLASS,STUDENTID值的SCORE值累积计算,结果作为F1列的值:
|
|
3 |
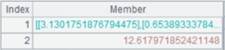
使用@z选项,逆向计算:
|

注意:
new()和derive()的区别:new()是重新构造了一个序表,不改变原序表;而derive()方法是先抄录原有字段再增加字段。
r.derive()
描述:
为记录添加字段。
r.derive(xi :Fi,…)
备注:
给记录r增加Fi,…字段,Fi赋值为xi,返回由原字段与新增字段Fi组成的新记录。
参数:
|
Fi |
字段名,此时Fi不能与r中原有字段同名。 |
|
xi |
表达式,计算结果作为字段值。 |
|
r |
记录。 |
返回值:
记录
示例:
|
|
A |
|
|
1 |
=demo.query("select top 9 class,studentid,subject,score from scores") |
返回序表数据如下:
|
|
2 |
=A1(1) |
返回序表A1中的第1条记录:
|
|
3 |
=A2.derive("MARY":NAME,"F":gender) |
在A2记录中增加新字段NAME与gender,返回新记录:
|
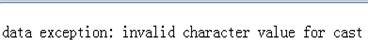

P.derive()
描述:
由排列生成序表。
语法:
P.derive()
备注:
由排列P产生一个数据结构相同的序表,以便使用序表相关的函数。
参数:
|
P |
排列 |
选项:
|
@o |
不复制,将改变记录的指向结构,字段数不匹配者也被调整。 性能更好但有出错风险,仅在原记录所在序表可丢弃时使用。 排列中有纯序表记录时不可执行此动作。 |
返回值:
序表
示例:
|
|
A |
|
|
1 |
=demo.query("select * from SCORES") |
|
|
2 |
=A1.select(SCORE>90) |
结果为排列。 |
|
3 |
=A2.derive() |
由排列生成序表。 |
|
4 |
=A2.derive@o() |
直接引用排列中的记录而不是产生新记录。 |
ch.derive()
管道附加增添字段动作后返回原管道。
语法:
ch.derive(xi :Fi,…)
备注:
管道ch附加计算,对ch的每条记录计算表达式xi,xi作为新字段Fi的值,形成ch的原字段和Fi,…组成的原管道。
参数:
|
Ch |
管道。 |
|
Fi |
字段名,此时Fi不能与ch中原有字段同名。 |
|
Xi |
表达式,计算结果作为字段值。 |
选项:
|
@i |
有xi且计算结果为空时不生成该行记录。 |
返回值:
管道
示例:
|
|
A |
|
|
1 |
=demo.cursor("select NAME,BIRTHDAY,HIREDATE from Employee") |
|
|
2 |
=file("D:\\txt_files\\data1.txt").cursor@t() |
data1.txt中内容如下:
|
|
3 |
=channel() |
创建管道。 |
|
4 |
=channel() |
创建管道。 |
|
5 |
=A3.derive(interval@y(BIRTHDAY,HIREDATE):EntryAge, age(HIREDATE):WorkAge) |
管道A3附加计算,在原管道的基础上添加EntryAge和WorkAge字段,返回原管道。 |
|
6 |
=A3.fetch() |
A3管道执行结果集函数,保留管道当前数据。 |
|
7 |
=A4.derive@i(SCORE:score_not_null) |
管道A4附加计算,SCORE为空时,对应的该条记录不生成。 |
|
8 |
=A4.fetch() |
A4管道执行结果集函数,保留管道当前数据。 |
|
9 |
=A1.push(A3) |
将游标A1中的数据推送到管道A3,此时数据不会立即被推送到管道。 |
|
10 |
=A2.push(A4) |
将游标A2中的数据推送到管道A4,此时数据不会立即被推送到管道。 |
|
11 |
=A1.skip() |
A1游标执行取数动作,此时数据才会被推送到管道A3,然后管道执行计算并记录结果。 |
|
12 |
=A2.fetch() |
A2游标执行取数动作,此时数据才会被推送到管道A4,然后管道执行计算并记录结果。 |
|
13 |
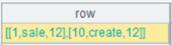
=A3.result() |
获取A3管道计算结果:
|
|
14 |
=A4.result() |
获取A4管道计算结果:
|

cs.derive()
游标中附加增添字段动作后返回原游标。
语法:
cs.derive(xi :Fi,…)
备注:
游标cs附加计算,对cs的每条记录计算表达式xi,xi作为新字段Fi的值,把原字段和Fi组成的新序表返回到原游标cs中。
参数:
|
Cs |
游标。 |
|
Fi |
字段名,此时Fi不能与cs中原有字段同名。 |
|
Xi |
表达式,计算结果作为字段值。 |
选项:
|
@i |
有xi且计算结果为空时不生成该行记录。 |
返回值:
游标
|
|
A |
|
|
1 |
=demo.cursor("select NAME,BIRTHDAY,HIREDATE from Employee") |
返回游标。 |
|
2 |
=A1.derive(interval@y(BIRTHDAY,HIREDATE):EntryAge, age(HIREDATE):WorkAge) |
A1游标附加新增字段计算,新的字段EntryAge和WorkAge与A1中的原字段组成序表返回到A1原游标中。 |
|
3 |
=A1.fetch() |
读取游标A1执行A2计算后的数据(数据量较大时建议分批读取):
|
|
4 |
=file("D:\\txt_files\\data1.txt").cursor@t() |
data1.txt中内容如下:
|
|
5 |
=A4.derive@i(SCORE:score_not_null) |
使用@i选项,SCORE计算结果为空时,对应的记录不生成。 |
|
6 |
=A4.fetch() |
读取A4游标执行A5计算后的数据:
|



T.derive()
描述:
虚表中定义添加字段操作后返回新虚表。
语法:
T.derive(xi :Fi,…)
备注:
虚表T中定义计算,对T计算表达式xi ,结果作为新字段Fi,…的字段值,返回 T的原字段和Fi,…组成的新虚表。
参数:
|
T |
虚表。 |
|
Fi |
字段名,此时Fi不能与T中原有字段同名。 |
|
Xi |
表达式,计算结果作为字段值。 |
选项:
|
@i |
返回值:
虚表
|
|
A |
|
|
1 |
emp.ctx组表内容如下:
|
|
|
2 |
=pseudo(A1) |
生成虚表对象。 |
|
3 |
=A2.derive(interval@y(BIRTHDAY,HIREDATE):EntryAge, age(HIREDATE):WorkAge) |
A2虚表中定义计算,在原虚表的基础上添加EntryAge和WorkAge字段,返回新虚表。 |
|
4 |
=A3.import() |
读取A3虚表中的数据,此时A2虚表执行A3中定义的计算操作,返回内容如下:
|