
A.select()
描述:
选出序列中符合条件的成员。
语法:
|
A.select( x ) |
|
|
A.select(x1:y1, x2:y2, ......xi:yi) |
多个条件时用&&组合查询的简化写法,相当于A.select(x1== y1 && x2== y2 &&...... xi==yi)。 |
备注:
针对序列A的每个成员计算表达式x,返回使表达式的值为真的成员组成的新序列。参数省略时返回所有成员。
注意,当序列中的列名与单元格格名冲突时,表达式中引用列名时需要加上序列名称作为前缀。
选项:
|
@1 |
返回第一个成员,找不到符合条件的成员时返回null。 |
|
@z |
从后往前查找。 |
|
@b |
使用二分法查询,要求A必须是升序序列,并且参数必须是使用x:y格式或者是返回数值的表达式,数值表达式结果为0则表示找到。 |
|
@m |
数据量大的复杂运算中并行计算提升性能,计算次序不确定,与@1bz选项互斥。 |
|
@t |
当A是序表且返回值为空时,返回一个保留数据结构的空序表。 |
|
@c |
从第一成员开始取,到第一个不满足x为真的成员停止。 |
|
@r |
从前往后查找第一个满足条件的成员,然后从这个成员一直取到序列的最后一个成员。 |
|
@v |
A是纯序表时,返回成纯序表,该选项缺省时返回纯序列。仅企业版适用。 |
|
@0 |
找不到符合条件的成员时返回null,该选项缺省时返回空序列。 |
参数:
|
A |
序列。 |
|
x |
布尔表达式,可为null。 |
|
xi:yi |
xi 为表达式,yi为比较值。 |
返回值:
序列/序表
示例:
|
|
A |
|
|
1 |
[2,5,4,3,2,1,4,1,3] |
|
|
2 |
=A1.select(~>3) |
[5,4,4] |
|
3 |
=A1.select@1(~>3) |
5,返回符合条件的第一个成员。 |
|
4 |
=demo.query("select EID,NAME,GENDER,DEPT,SALARY from EMPLOYEE order by EID") |
|
|
5 |
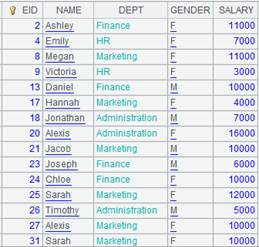
=A4.select(GENDER:"F",SALARY:16000) |
多条件查询:
|
|
6 |
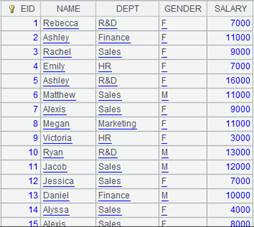
=A4.select@t(EID==2000) |
返回一个保留数据结构的空序表:
|
|
7 |
=A1.select (~>8) |
返回空序列。 |
|
8 |
=A1.select@0(~>8) |
返回null。 |
指定查询方向:
|
|
A |
|
|
1 |
[2,5,4,3,2,1,4,1,3] |
|
|
2 |
=A1.select(~>3) |
[5,4,4] |
|
3 |
=A1.select@z(~>3) |
[4,4,5],从后往前查。 |
|
4 |
[8,10,3,5,7,9,11,13,7] |
|
|
5 |
=A4.select@c(~>7) |
[8,10],从第一个成员往后取,到第一个不满足条件的成员停止。 |
|
6 |
=A4.select@zc(~>6) |
[7,13,11,9,7],从最后一个成员往前取,到第一个不符合条件的成员停止。 |
|
7 |
=A4.select@r(~>10) |
[11,13,7],从前往后查找第一个满足条件的成员,然后从这个成员一直取到最后。 |
高效率筛选:
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,GENDER,DEPT,BIRTHDAY from employee") |
|
|
2 |
=A1.select@m(GENDER=="F") |
使用@m选项,数据量大时使用并行计算,提升性能。 |
|
3 |
=A1.sort(GENDER).select@b(GENDER:"F") |
将A1根据GENDER升序排序,此时可使用二分法查询,表达式中使用冒号,查询GENDER值为F的数据。 |
|
4 |
=A1.sort(EID).select@b(EID-10) |
将A1根据EID升序排序,此时可使用二分法查询,参数使用返回数值的表达式,查询EID为10的数据。 |
列名与格名冲突的情况:
|
|
A |
|
|
1 |
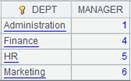
=to(3).new(~:ID,~*~:A1) |
|
|
2 |
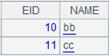
=A1.select(A1.A1==4) |
当列名与格名冲突时,表达式中引用列名需要加上序列名称作为前缀。
|
返回纯序表 :
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,GENDER,DEPT,BIRTHDAY from employee").keys(EID) |
|
|
2 |
=A1.i() |
将序表A1转换为纯序表。 |
|
3 |
=A2.select(GENDER=="M") |
返回结果类型为纯序列。 |
|
4 |
=A2.select@v(GENDER=="F") |
使用@v选项,返回结果类型为纯序表。 |
相关概念: