
A.new( xi : Fi ,…)
描述:
计算序列后生成新序表。
语法:
A.new(xi:Fi,…)
备注:
对序列A计算表达式xi,生成一个记录数与A相同,且字段值为xi、字段名为Fi的新序表。
参数:
|
Fi |
结果序表的字段名,缺省用xi ,当xi为#i时使用原列名。 |
|
xi |
表达式,结果作为字段值,缺省为null,省略xi时,不能省略: Fi。 |
|
A |
序列。 |
选项:
|
@m |
并行计算提升性能。 |
|
@i |
有xi并且计算结果为空时,不生成该行记录。 |
|
@o |
A是纯序表时,未改变的旧列直接引用,不再新产生,对结果序表进行更新操作时,会同时更新A的内容。仅企业版适用。 |
|
@z |
逆向计算,仅适用于非纯序列。 |
返回值:
序表
示例:
Ø 从单个序表产生
|
|
A |
|
|
1 |
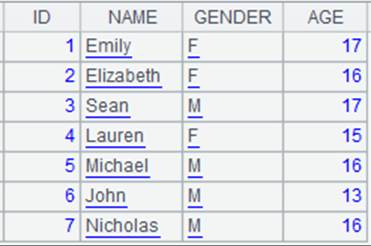
=demo.query("select EID,NAME,DEPT,BIRTHDAY from EMPLOYEE") |
|
|
2 |
=A1.new(EID:EmployeeID,NAME, #3:dept) |
直接产生新序表,如与A1字段名相同,可以省略Fi。 |
|
3 |
=A1.new(NAME,age(BIRTHDAY):AGE) |
计算字段值生成新序表。 |
|
4 |
=A1.new@m(NAME,age(BIRTHDAY):AGE) |
数据量大时提升性能。 |
|
5 |
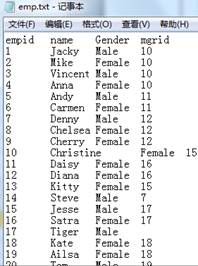
=file("D:\\txt_files\\data1.txt").import@t() |
data1.txt中内容如下:
|
|
6 |
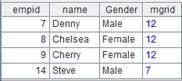
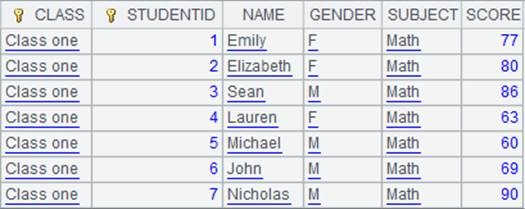
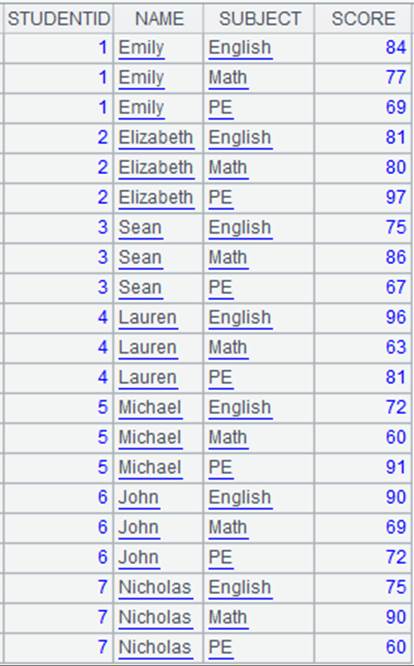
=A5.new@i(CLASS,STUDENTID,SUBJECT,SCORE:score) |
SCORE计算结果为空时,对应的该条记录不生成:
|
Ø A为纯序表时
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,DEPT,BIRTHDAY from EMPLOYEE").i() |
返回纯序表。 |
|
2 |
=A1.new@o(EID,NAME, #3:dept) |
|
|
3 |
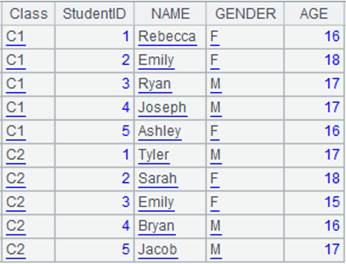
=A2(1).NAME="aaa" |
修改列值时会同时修改源表的,执行后A2格结果如下:
此时A1格结果如下:
|

Ø 从同序的多个序表关联运算产生
|
|
A |
|
|
1 |
=create(Name,Chinese).record(["Jack",99,"Lucy",90]) |
|
|
2 |
=create(Name,Math).record(["Jack",89,"Lucy",96]) |
|
|
3 |
=A1.new(Name:Name,Chinese:Chinese,A2(#).Math:Math) |
通过A2(#)读取A2同位置的记录 |

Ø 逆向计算
|
|
A |
|
|
1 |
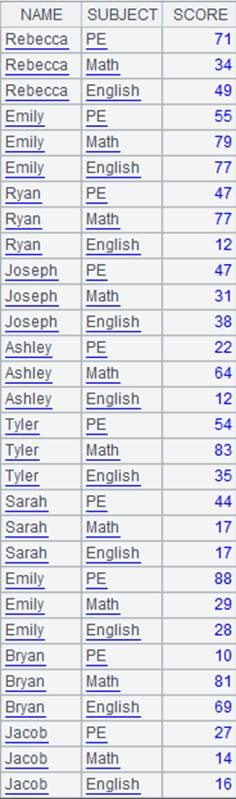
=demo.query("select * from SCORES ") |
返回序表:
|
|
2 |
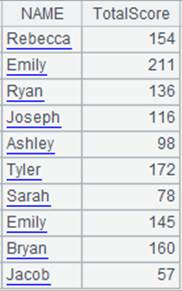
=A1.new(CLASS,STUDENTID,SUBJECT,SCORE,cum(SCORE;CLASS,STUDENTID):F1) |
循环函数中迭代运算,对有相同CLASS,STUDENTID值的SCORE值累积计算,结果作为F1列的值,返回的新序表如下:
|
|
3 |
=A1.new@z(CLASS,STUDENTID,SUBJECT,SCORE,cum(SCORE;CLASS,STUDENTID):F1) |
使用@z选项,逆向计算:
|
相关概念: