align()
本章介绍align()函数的多种用法。
P.align(A:x,y)
描述:
将排列按照序列对齐。
语法:
P.align(A:x,y)
备注:
通过关联表达式x和y,将排列P的记录按照序列A对齐。
该函数主要应用于主子表的情况,y表达式通常是子表P的外键字段,x是主表A的主键字段 ,根据y与x对比 ,相同则对齐。
常规情况下,主子表之间是一对多的关系,即A中一条记录对应P中多条记录。
x,y省略时,以P当前记录与A中成员对齐。
参数:
|
P |
排列/序表/纯序表,一般可看作子表。 |
|
A |
用于对齐的序列或排列,一般可看作主表。 |
|
x |
A中用于关联的字段或者字段表达式,缺省解释为~。 |
|
y |
P中用于关联的字段或者字段表达式,缺省解释为~。 |
选项:
|
@a |
P中所有记录按照A分组对齐,将各组记录作为一个序列成员返回到结果序列中。选项缺省时返回每组的第一个成员组成的序列。 |
|
@b |
当A是有序序列时,使用二分法查询。 |
|
@p |
返回序列由成员在P中的序号构成。 |
|
@n |
返回P记录按照A成员对齐的所有成员,结果集最后一组用于存放P中对不上的成员。 |
|
@s |
P中记录按照A中成员的次序排序,其中无法与A对应的成员排在最后。 |
|
@v |
P是纯序表时,返回成纯序表。仅企业版适用。 |
|
@o |
A和P都有序,用归并方式对齐。 |
返回值:
序列/排列/纯序表
示例:
Ø 子表向主表对齐后计算
|
|
A |
|
|
1 |
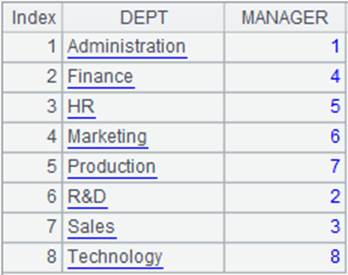
=demo.query("select * from DEPARTMENT ") |
可看作主表:
|
|
2 |
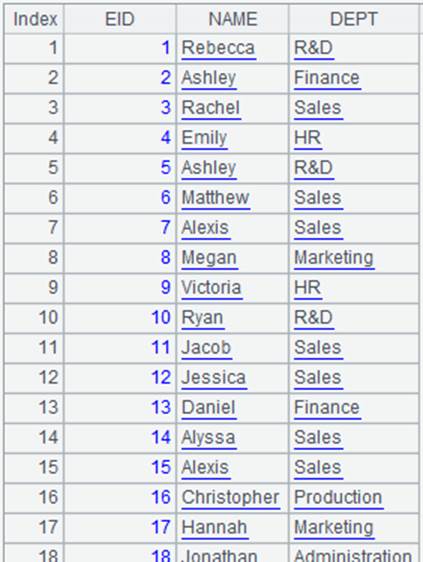
=demo.query("select * from EMPLOYEE ") |
可看作子表,与A1的关联字段为DEPT:
|
|
3 |
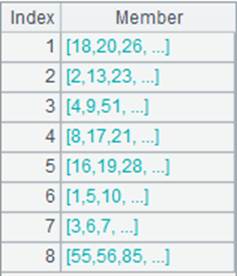
=A2.align@a(A1:DEPT,DEPT) |
将EMPLOYEE表按照DEPARTMENT表对齐,表关联字段为DEPT,使用@a选项,返回所有成员:
|
|
4 |
=A1.new(DEPT, A3(#).count():NUMBER) |
将A3和A1关联计算,列出对齐后每组中子表EMPLOYEE的记录条数:
|
|
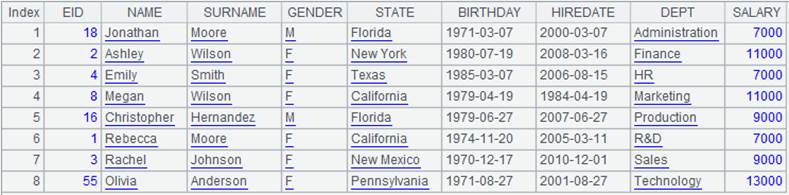
5 |
=A2.align(A1:DEPT,DEPT) |
选项缺省,只返回每组第一个成员组成的序列:
|

Ø 用于特殊排序
|
|
A |
|
|
1 |
=demo.query("select * from score") |
|
|
2 |
=A1.sort(class) |
使用sort按照class排序,class字段按照four/one/three/two展示:
|
|
3 |
=A1.group(class) |
使用group按照class分组,class字段按照four/one/three/two展示,使用该方式,无法指定分组顺序:
|
|
4 |
=["class one","class two","class three","class four"] |
|
|
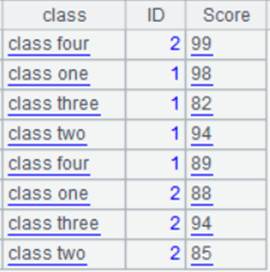
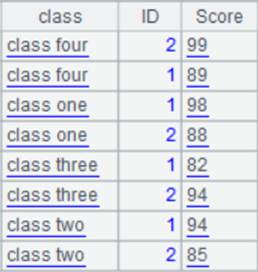
5 |
=A1.align@a(A4,class) |
使用align@a选项对齐所有成员,省略x参数,使A1按照其class字段在A4中的次序排序,并且把结果序列分组:
|

Ø @b选项,使用二分法
|
|
A |
|
|
1 |
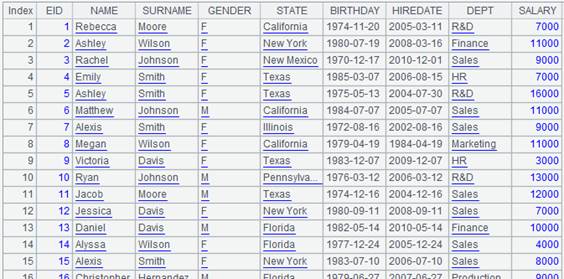
=demo.query("select * from FAMILY").sort(EID) |
|
|
2 |
=demo.query("select top 11 * from EMPLOYEE") |
|
|
3 |
=A1.align@ba(A2:EID,EID) |
A1对EID有序,使用二分法加快查询速度:
|
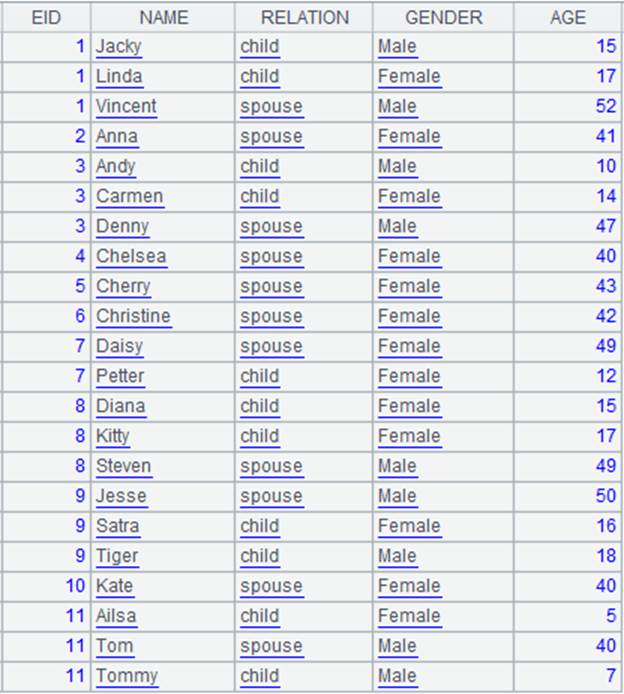
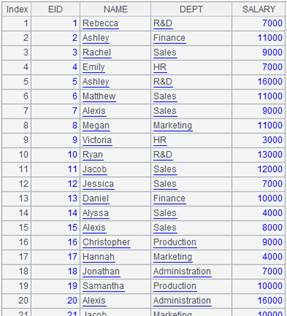
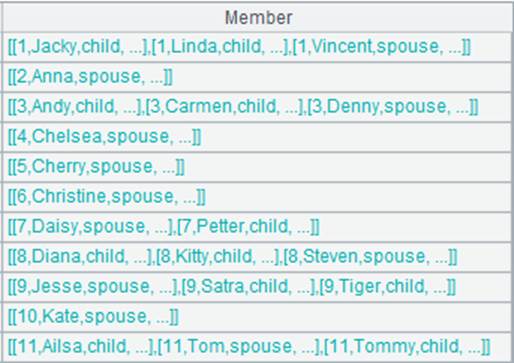
Ø @p选项,对齐后的结果集由成员在P中的序号构成
|
|
A |
|
|
1 |
=demo.query("select * from DEPARTMENT ") |
|
|
2 |
=demo.query("select EID,NAME,DEPT,SALARY from EMPLOYEE ") |
|
|
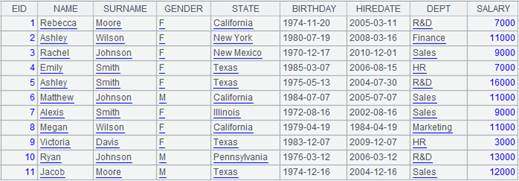
3 |
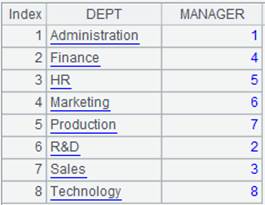
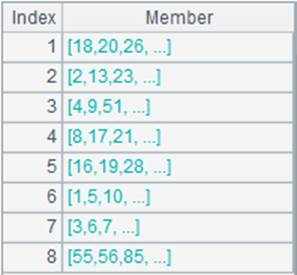
=A2.align@ap(A1:DEPT,DEPT) |
A2按照A1对齐后,结果返回P成员序号构成的序列:
|

Ø @n选项:
|
Ø |
A |
|
|
1 |
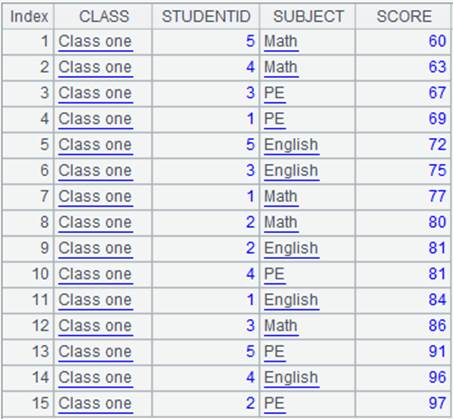
=demo.query("select top 15 * from SCORES") |
|
|
2 |
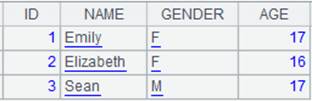
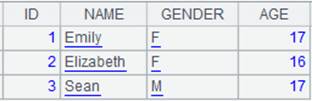
=demo.query("select top 3 * from STUDENTS") |
|
|
3 |
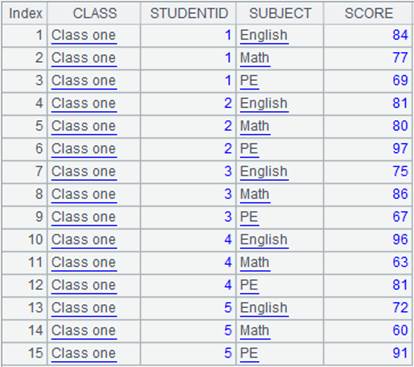
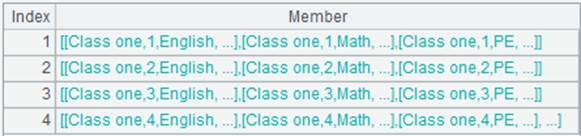
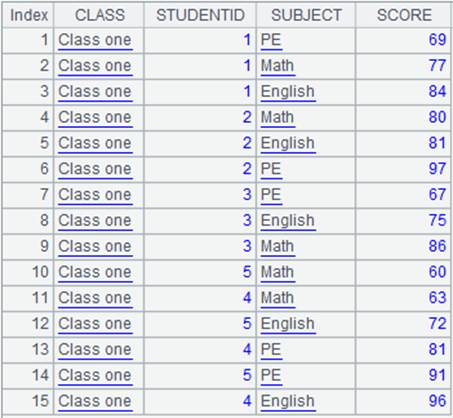
=A1.align@n(A2:ID,STUDENTID) |
使用@n选项,将主表和子表对齐返回所有成员,最后一组存放子表中无法与主表对应的成员:
|
Ø @s选项,将子表记录按照主表成员排序。
|
|
A |
|
|
1 |
=demo.query("select top 9 * from SCORES").sort(SCORE) |
|
|
2 |
=demo.query("select top 3 * from STUDENTS") |
|
|
3 |
=A1.align@s(A2:ID,STUDENTID) |
使用@s选项,将A1表按照A2的ID进行排序,对应不上的成员放到最后:
|
P.align(n,y)
描述:
语法:
P.align(n,y)
备注:
排列P按照分组表达式y划分为n个组,计算y后的结果与分组号相同则对齐,等同于P.align(to(n),y)。
参数:
|
P |
排列。 |
|
n |
整数,表示分组个数。 |
|
y |
整数或整数数列。 |
选项:
|
@a |
返回分组后的所有成员,每组成员组成一个序列。选项缺省时仅返回每组的第一个成员。 |
|
@r |
y为整数数列,y中每个成员作为对齐位置,将P重复分组到n中指定位置。 |
|
@p |
返回的序列由P成员在P中的序号构成。 |
返回值:
序列
示例:
|
|
A |
|
|
1 |
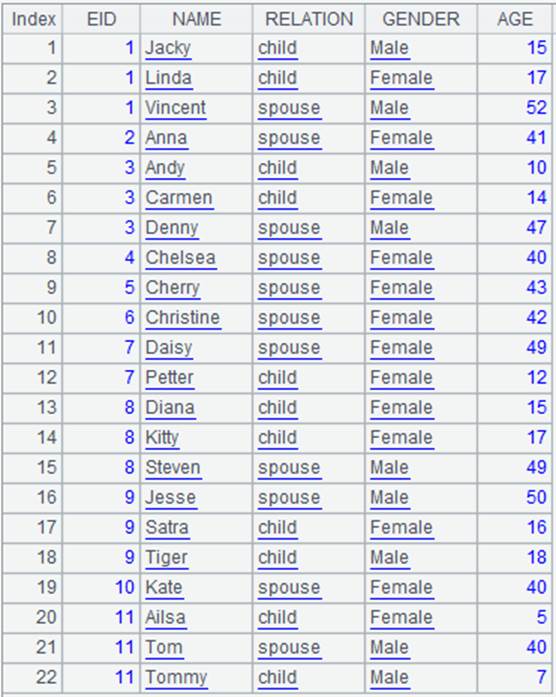
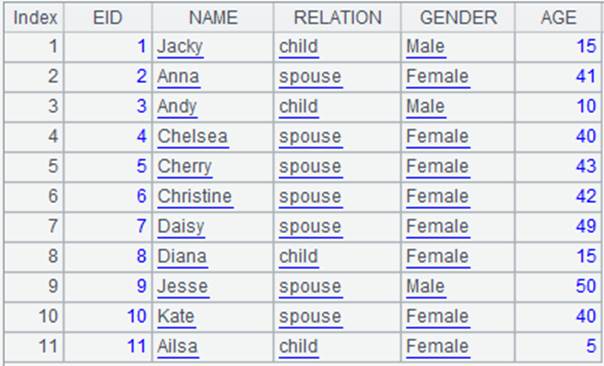
=demo.query("select * from FAMILY") |
|
|
2 |
=A1.align(11,EID) |
将A1排列根据EID值分为11组,EID值与分组号一一对应,结果仅返回每组的第一个成员:
|
|
3 |
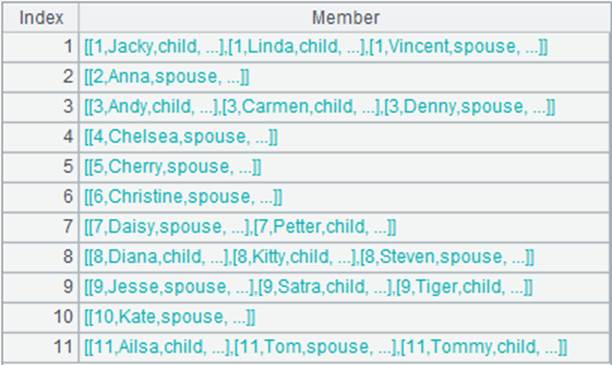
=A1.align@a(11,EID) |
将A1排列根据EID值分为11组,EID值与分组号一一对应,使用@a选项,返回每组中所有成员:
|
|
4 |
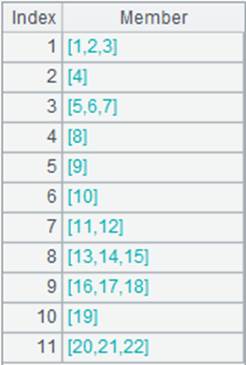
=A1.align@ap(11,EID) |
使用@p选项,返回值由EID在A1中的序号构成:
|
y为整数数列:
|
|
A |
|
|
1 |
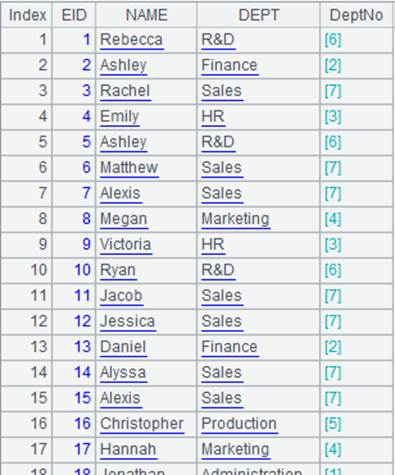
=demo.query("select EID,NAME,DEPT from EMPLOYEE") |
|
|
2 |
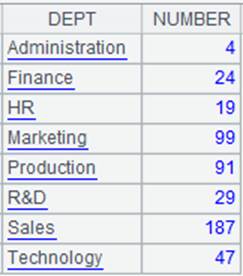
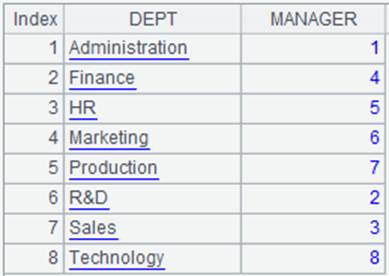
=demo.query("select * from DEPARTMENT") |
|
|
3 |
先找出与EMPLOYEE表对应的DEPARTMENT记录序号,把序号作为数列存储在DeptNo字段中:
|
|
|
4 |
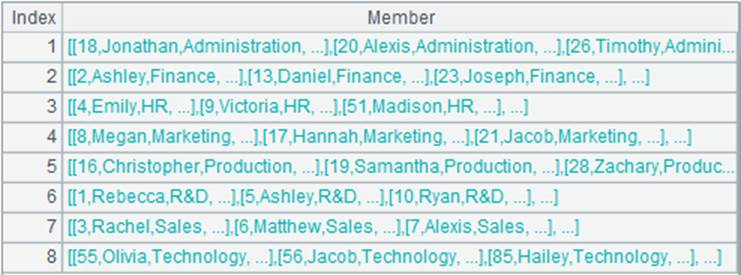
=A3.align@r(8,DeptNo) |
利用DeptNo字段直接和分组号对齐:
|
|
5 |
=A3.align@rp(8,DeptNo) |
增加@p选项,返回记录序号:
|