P.join()
描述:
序表与排列外键式连接。
语法:
P.join(C:.,T:K,x:F,…; …;…)
备注:
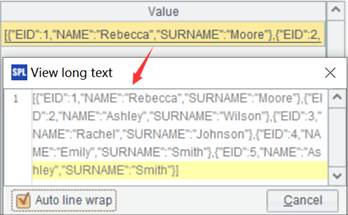
用序表/排列P的字段C,…匹配序表/排列T的键找到相应记录,在P上拼接T中的表达式x,作为字段F添加到P 上形成新序表。
K只能省略或者是#,K省略时默认为T的键,T有索引则使用索引,无索引则建立临时索引;K值为#时表示用T表记录的序号,即外键序号化处理,简单概括就是维表的主键是从1开始的自然数,也就是表记录所在行号,这种情况下就可以用键值直接按行号定位维表记录,从而加快与维表关联的速度,进一步提升性能。
如果F在P中已存在则改写现有字段。时间键值被省略时用now()。
选项:
|
@i |
匹配不上的外键删除整条记录,缺省将填成null。当参数x:F省略时,只做针对P的过滤操作。 |
|
@d |
删除匹配上外键的整条记录,只做针对P的过滤操作,此时省略参数x:F。 |
|
@m |
P对C有序,T对K有序,此时可用归并方式计算。 |
参数:
|
P |
序表/排列。 |
|
C |
P的外键,多个时以冒号隔开。 |
|
T |
|
|
K |
T的键。 |
|
x |
T的字段表达式,x可以是~和#,#表示记录在T中的序号,找不到填为null。 |
|
F |
表达式x的字段名。 |
返回值:
序表/排列
示例:
|
|
A |
|
|
1 |
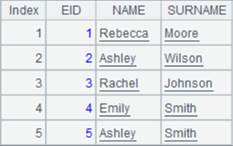
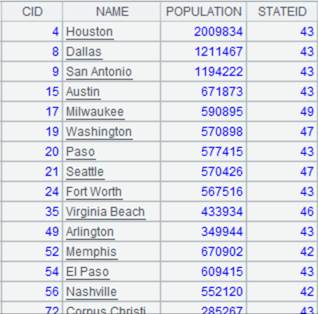
=connect("demo").query("SELECT * FROM CITIES") |
CITIES表数据内容:
|
|
2 |
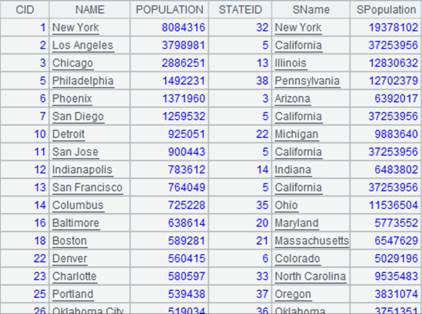
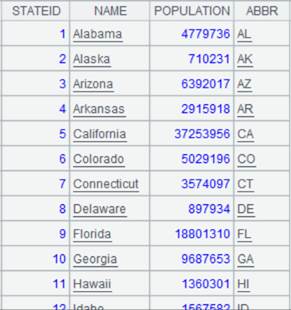
=connect("demo").query("SELECT * FROM STATECAPITAL where STATEID<30").keys(STATEID) |
STATECAPITAL表数据内容:
|
|
3 |
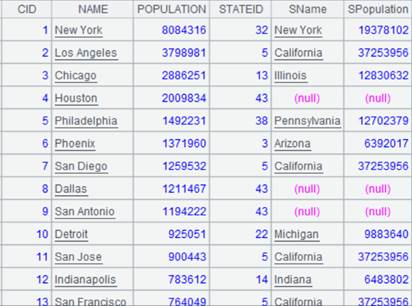
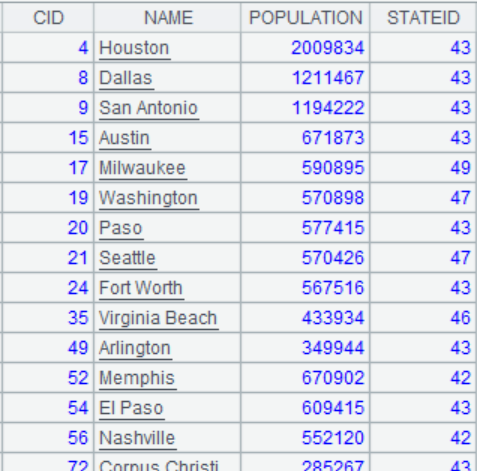
=A1.join(STATEID,A2,CAPITAL) |
将CITIES表与STATECAPITAL表外键式连接,参数K缺省为的STATECAPITAL键,即STATEID,并将STATECAPITAL表中的字段CAPITAL拼接到中成为新序表:
|
|
4 |
=A1.join(STATEID,A2:#,CAPITAL) |
可以看到STATEID字段是从1开始的自然数,与STATECAPITAL表的记录号是一致的,所以可以将参数K设为#,表示用STATECAPITAL表的序号,可提高计算效率,返回结果与A3相同。 |
|
5 |
=A1.join@i(STATEID,A2,CAPITAL) |
使用@i选项,匹配不上的外键删除整条记录,缺省将填成null:
|
|
6 |
=A1.join@i(STATEID,A2) |
使用@i选项,当参数x:F省略时,只做针对CITIES表的过滤操作:
|
|
7 |
=A1.join@d(STATEID,A2) |
使用@d选项,当参数x:F省略时,删除匹配上外键的整条记录,只做针对CITIES表的过滤操作:
|
|
8 |
=A1.join(STATEID,A2,abc) |
x参数值在A2中找不到则填为nul:
|
|
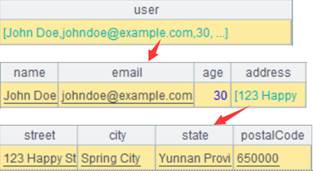
9 |
如果NAME在CITIES表中已存在则改写现有字段:
|

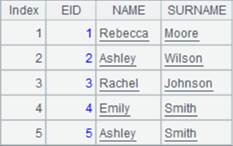
归并方式计算:
|
|
A |
|
|
1 |
=connect("demo").query("SELECT * FROM CITIES").sort(STATEID) |
CITIES表数据内容:
|
|
2 |
=connect("demo").query("SELECT * FROM STATECAPITAL where STATEID<30").keys(STATEID).sort(STATEID) |
STATECAPITAL表数据内容:
|
|
3 |
=A1.join@m(STATEID,A2,CAPITAL) |
CITIES对STATEID有序,STATECAPITAL对K有序,使用@m选项,此时可用归并方式计算:
|