
A.group(x i ,…)
按xi,…做等值分组。
语法:
A.group(xi,…)
备注:
将序列A按照表达式xi,…等值分组,结果为组集构成的序列/排列。
选项:
|
@o |
只和相邻对比,相当于归并,结果集不再排序。 |
|
@1 |
取每个分组的第一条记录,组成排列后返回(注意是数字1,不是字母l),可以与@v配合使用。 |
|
@n |
x取值为分组序号,可直接定位;与@o互斥;将x<1的数据组丢弃。 |
|
@u |
结果集不再按x排序;与@o/@n互斥。 |
|
@i |
x是布尔表达式,如果x的结果为true则开始新的一组。相当于A.group@o(a+=if(x,1,0))中a=0且只有一个x。 |
|
@0 |
将x的计算结果为空的组丢弃,当只有一个x时可以用该选项,与@n一起使用时,也将空组丢弃。 |
|
@s |
分组后序列/排列和列,相当于A.group(xi,…).conj(),可以与@v配合使用。 |
|
@p |
返回组成员在A中位置构成的数列的序列。 |
|
@h |
用于分段有序的数据,可提高分组效率。 |
|
@v |
A为纯序表时,返回成纯序表构成的集合。仅企业版适用。 |
参数:
|
A |
序列。 |
|
xi |
分组表达式。 |
返回值:
序列/排列
示例:
Ø 对数列分组
|
|
A |
|
|
1 |
[6,9,12,15,16,5,1,7,8] |
|
|
2 |
=A1.group(~%2) |
[[6,12,16,8],[ 9,15,5,1,7]]数列被分为2组,一组成员除以2余数为0,另一组成员除以2余数为1。 |
|
3 |
=A1.group(~%2,~%3) |
[[6,12],[16],[8],[9,15],[1,7],[5]]按照多个表达式分组。 |
|
4 |
=[6,9,16,5,1,7,8].group@s(~%2) |
按照奇偶数分组后和列:
|
|
5 |
=A1.group((#-1)\3) |
对序列A1分组,每3个一组:
|
Ø 对分组结果重复利用
|
|
A |
|
|
1 |
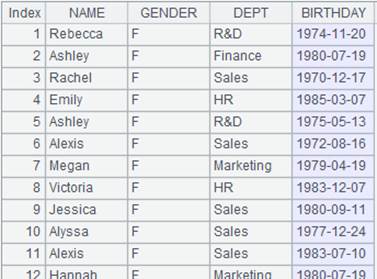
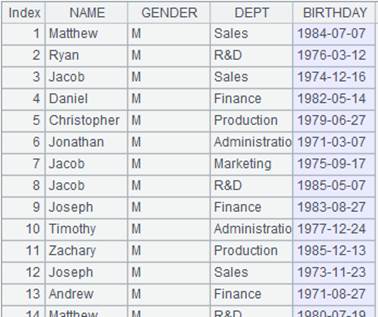
=demo.query("select NAME,BIRTHDAY,GENDER from EMPLOYEE") |
|
|
2 |
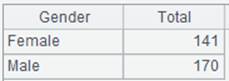
=A1.group(GENDER) |
A1序表根据GENDER分组:
点开分组后每个成员就是一个序列。
|
|
3 |
=A2.new(GENDER:Gender,~.count():Number) |
对分组后的成员统计。 |
|
4 |
=A2.new(GENDER:Gender,~.avg(age(BIRTHDAY)):Average) |
对分组结果重复利用,再次进行不同的统计。 |

Ø 多种分组方式
|
|
A |
|
|
1 |
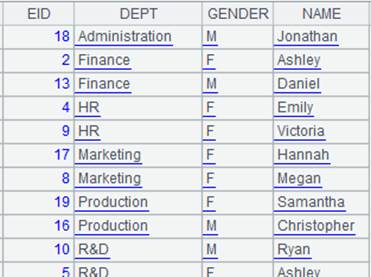
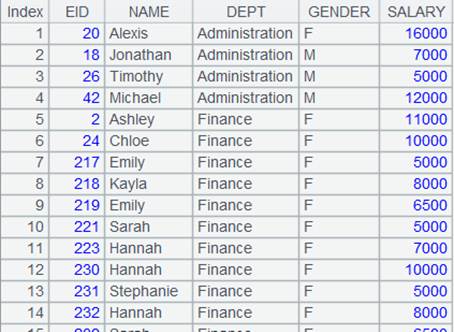
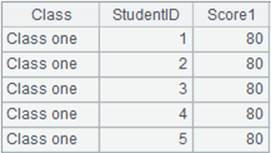
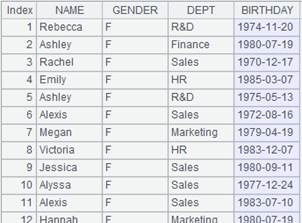
=demo.query("select NAME,GENDER,DEPT,BIRTHDAY from EMPLOYEE") |
|
|
2 |
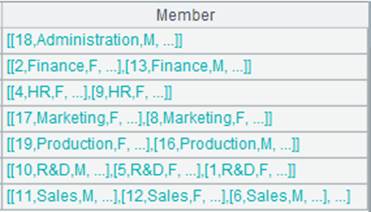
=A1.group(GENDER,DEPT) |
多字段分组。 |
|
3 |
=A1.group@o(GENDER) |
不排序,相邻的记录比较,相同的记录归为一组。不相邻但相同的记录可能变成两组,因此会出现重复的组,返回序列集。
|
|
4 |
=A1.group@1(GENDER) |
返回每组第一条记录:
|
|
5 |
=A1.group@n(if(GENDER=="F",1,2)) |
x取值为分组序号,可直接定位 [[Rebecca,Ashley,Rachel,…],[Matthew,Ryan,Jacob,…]]。 |
|
6 |
=A1.group@u(GENDER,DEPT) |
结果集不按分组字段排序。 |
|
7 |
=A1.group@i(GENDER=="F") |
遇到GENDER=="F"则开始新的分组。 |
|
8 |
=A1.group@p(GENDER,DEPT) |
返回按照字段GENDER,DEPT分组后,记录在原序表中的位置构成的序列。 |
|
9 |
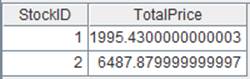
=file("D:\\Salesman.txt").import@t() |
|
|
10 |
=A9.group@0(Gender) |
按照字段Gender分组,为空的组丢弃不显示。 |
|
11 |
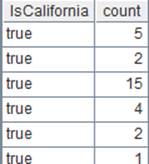
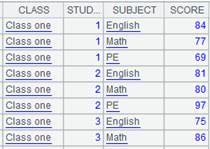
=file("D:/emp10.txt").import@t() |
数据文件emp10.txt中,每10条数据根据DEPT进行了一次排序:
|
|
12 |
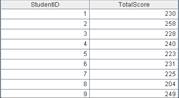
=A11.group@h(DEPT) |
A11是以DEPT分段有序的数据,使用@h选项提高分组效率:
|
|
13 |
=A1.group@n(if(DEPT=="HR":1,DEPT=="Sales":2;0)) |
使用@n选项,函数参数值小于1的数据丢弃,即将DEPT不为HR也不是Sales的数据组丢弃:
|


Ø A为序表
|
|
A |
|
|
1 |
=demo.query@v("select * from EMPLOYEE order by GENDER,DEPT ") |
返回纯序表。 |
|
2 |
=A1.group@v(GENDER,DEPT) |
使用@v选项,返回纯序表构成的集合。 |
相关概念: