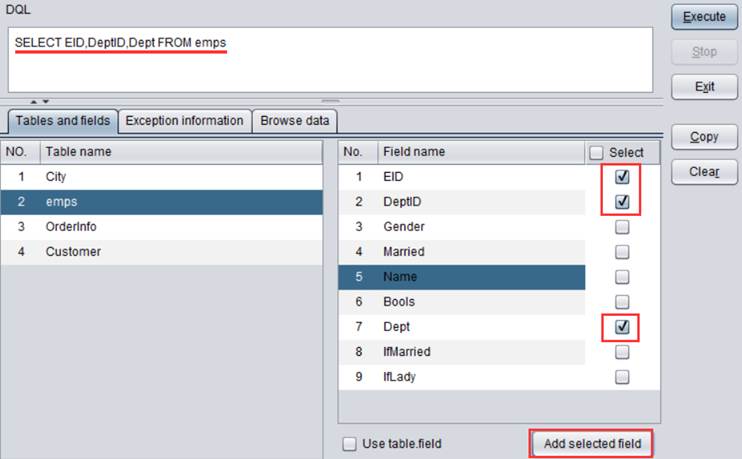
虚表的特殊字段定义
定义虚表时,可以使用物理表中的真字段,也可以根据真字段定义不同类型的伪字段,下面将通过几个示例详细介绍虚表特殊字段定义。
枚举维度型伪字段
在实际应用中,很多枚举类型字段的取值范围是字符串集合,物理表中一般会用整数来代替字符串。比如emps.ctx中的DeptID。整数比字符串占用空间小、运算速度快,但却无法像字符串那样通俗易懂。这种情况可以使用虚表的枚举维度型伪字段定义数值和字符串的对应关系。
打开快速入门章节中制作的demo.glmd,为虚表emps增加一个枚举类型字段Dept,存储真字段DeptID对应的显示值部门名称。
点击![]() 按钮,在User-defined field中增加一个特殊字段。Real
field name下拉列表中选择DeptID字段:
按钮,在User-defined field中增加一个特殊字段。Real
field name下拉列表中选择DeptID字段:
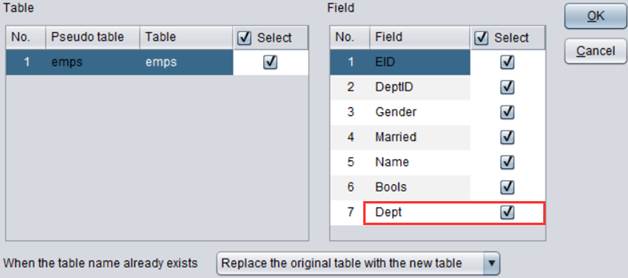
【Real field name】:用于设置真字段的字段名。物理表中存在的字段,被称为真字段。
编辑Enum dim pseudo field为Dept:
【Enum dim pseudo field】:用于设置枚举维度型伪字段名。
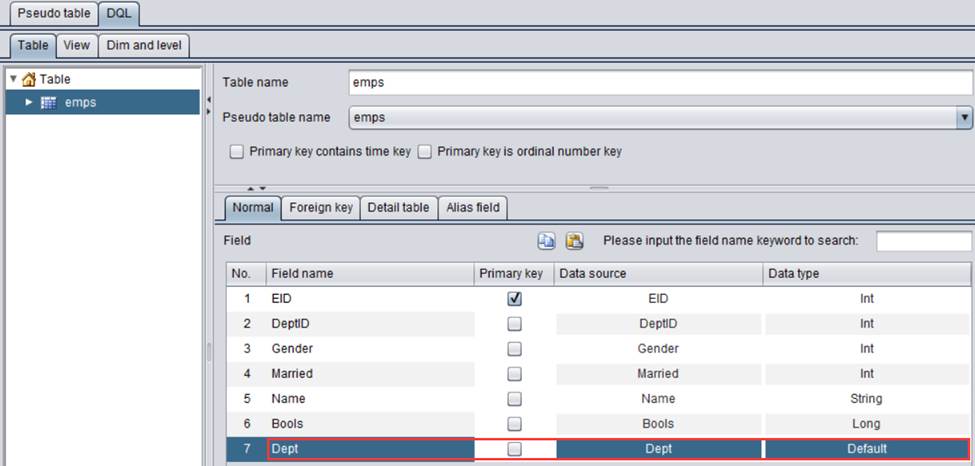
双击Enum dim value sequence:

设置DeptID对应的枚举值,从1开始,按位置对应,对应的编号转换为对应的值:
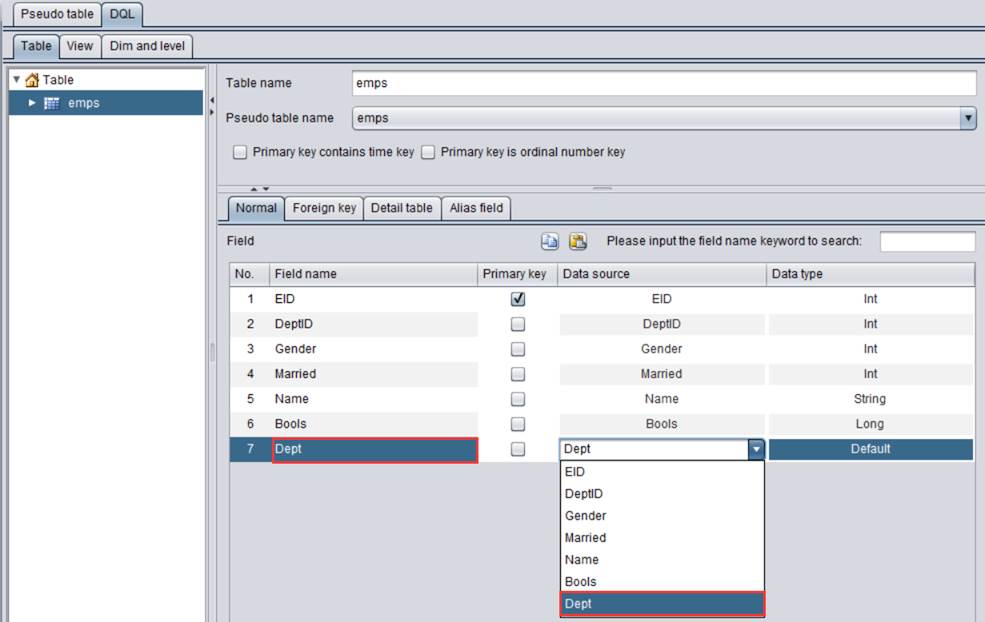
以上配置表示DeptID字段值1-5分别对应Dept伪字段值:["Sales","Technology","R&D","Financial","Admin"]。
【Enum dim value sequence】:用于设置枚举维度的取值序列。真字段为序号,伪字段取值是本序列成员。
点击【OK】后,特殊字段定义如下图:
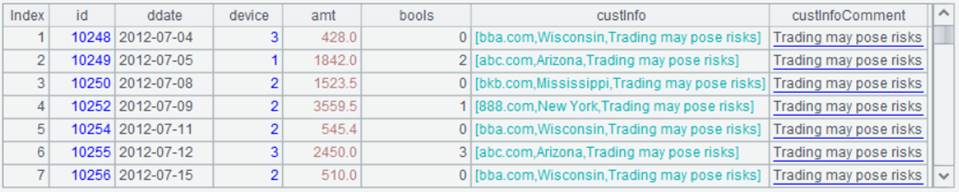
虚表字段有修改时,需将字段同步到DQL表,保存元数据文件后再做查询,同步方法有以下两种:
同步方法1:在菜单栏中点击Tool - Generate table from pseudo table,重新生成DQL表:
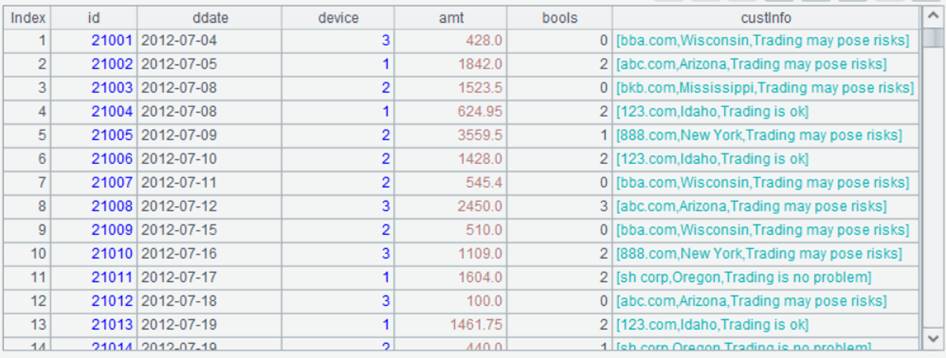
新生成的DQL表:
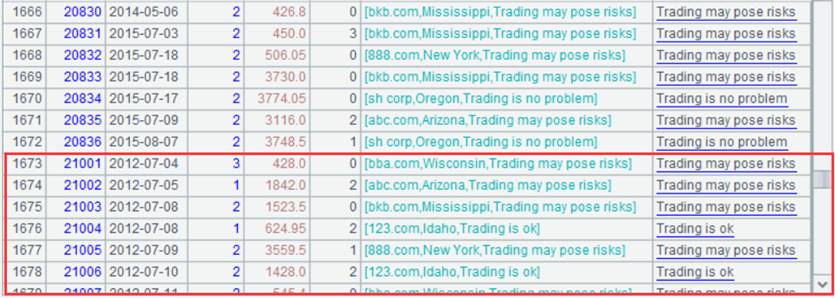
此方法比较快捷,但是会覆盖同名表,如果该表定义了外键,需在重新生成DQL表后重新定义外键。虚表变动比较大时可以使用该方法。
同步方法2:切换到DQL,点击![]() 在原DQL表中增加字段Dept,并在Data source下拉中选择虚表的变更字段Dept。
在原DQL表中增加字段Dept,并在Data source下拉中选择虚表的变更字段Dept。
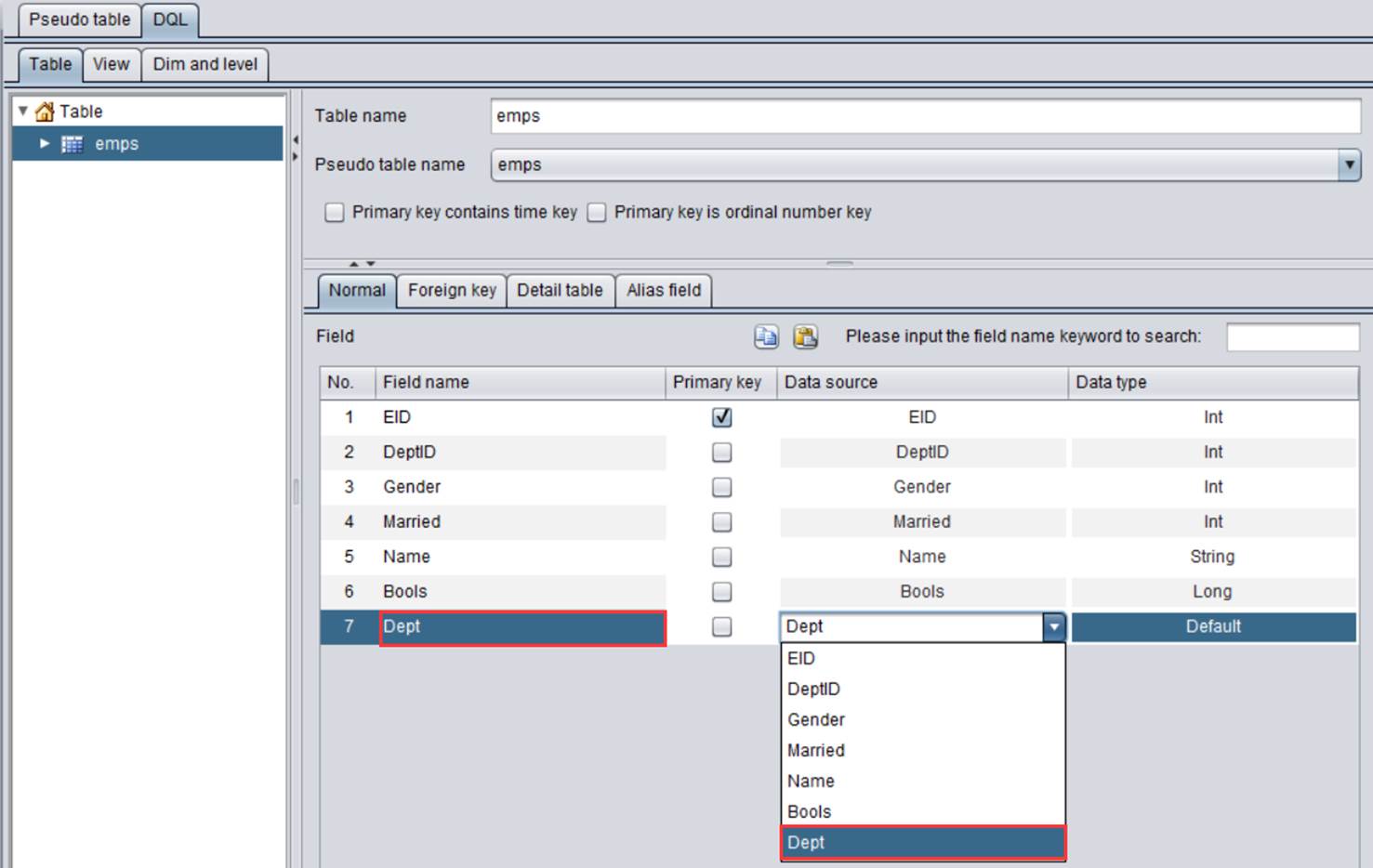
此方法比较灵活,适用于小变动,比如虚表个别字段增删,字段重命名等,不会影响外键。
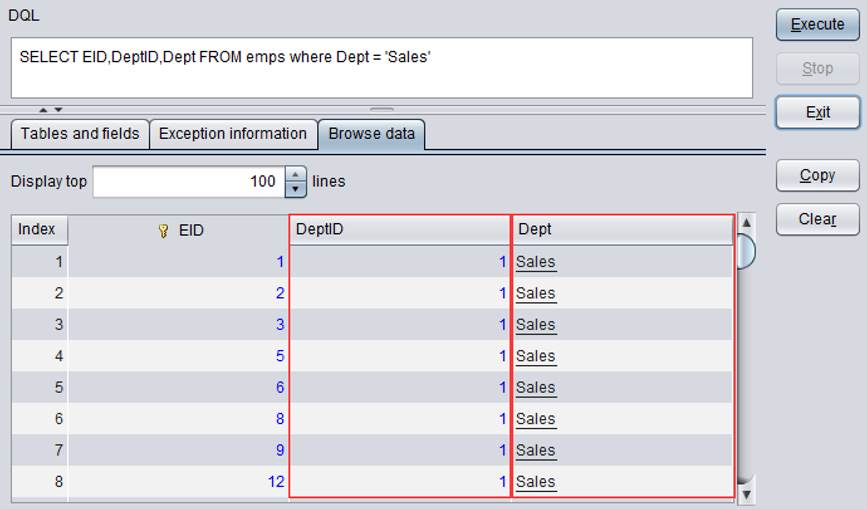
伪字段可以像真字段一样在DQL查询中使用。
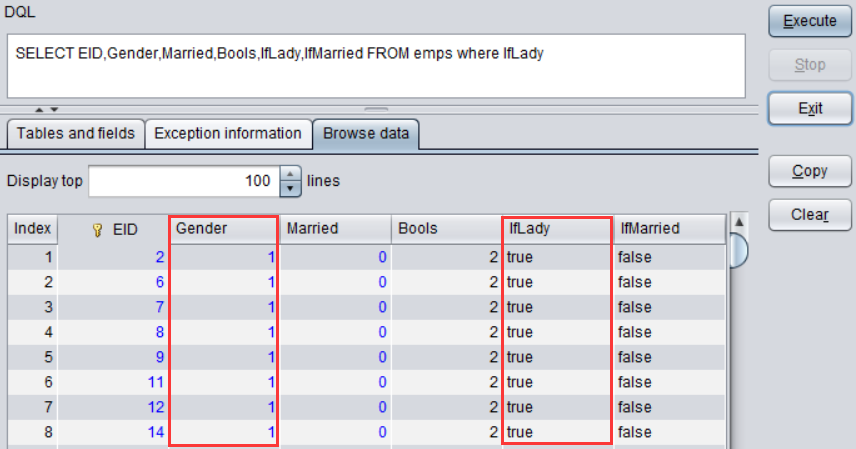
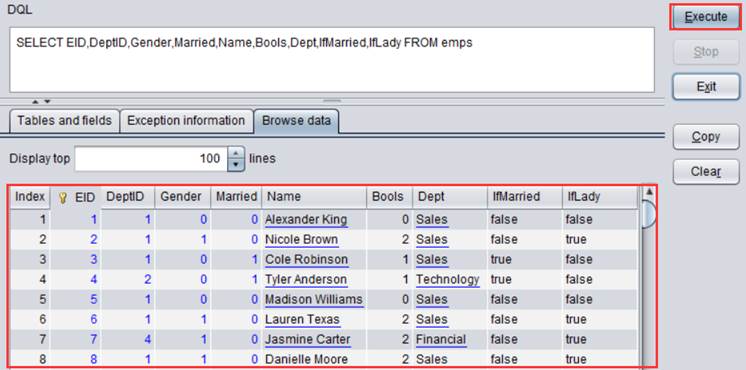
点击【Save】保存修改,再执行DQL查询,查询结果如下:
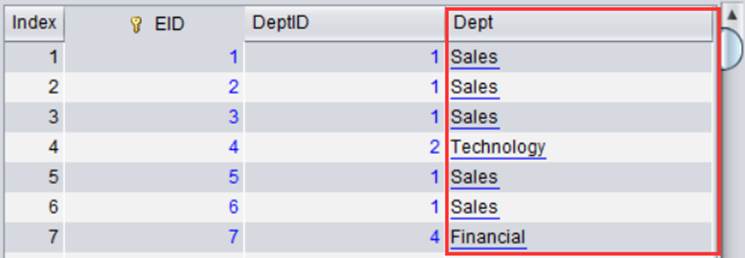
过滤条件中的字符串 Sales 会被程序自动转换为1,然后再用来过滤物理表:
二值维度伪字段
实际业务中,部分布尔(bool)类型字段的取值仅为true/false,存储时可用二值型字段(取值为 1 或 0)代替。但当此类bool字段数量较多时,会占用大量存储资源,此时物理表可通过二值维度型字段整合多个布尔字段,以优化存储效率。
比如emps.ctx中Bools字段存储了2个二值型字段的数据, Gender和Married。在Gender字段中,0表示男性,1表示女性;Married字段中,0表示未婚,1表示已婚。而Bools字段值则是经过bits(Gender,Married)计算的结果。
那么如何查询二值维度型字段的数据情况呢,此时可以借助于虚表的特殊字段定义,用伪字段定义二进制位和布尔值之间的映射关系,为虚表emps的二值维度字段Bools增加二值维度伪字段名,以便之后通过伪字段名查询过滤数据。
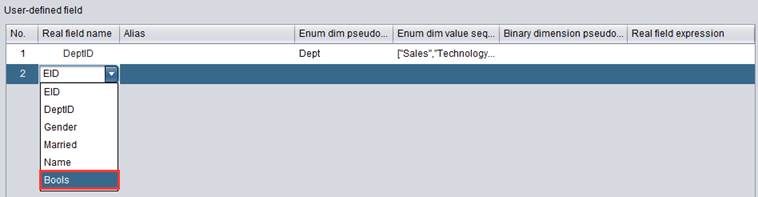
在打开的demo.glmd中点击![]() 按钮,在User–defined field中再增加一个特殊字段。Real field name下拉列表中选择Bools字段:
按钮,在User–defined field中再增加一个特殊字段。Real field name下拉列表中选择Bools字段:
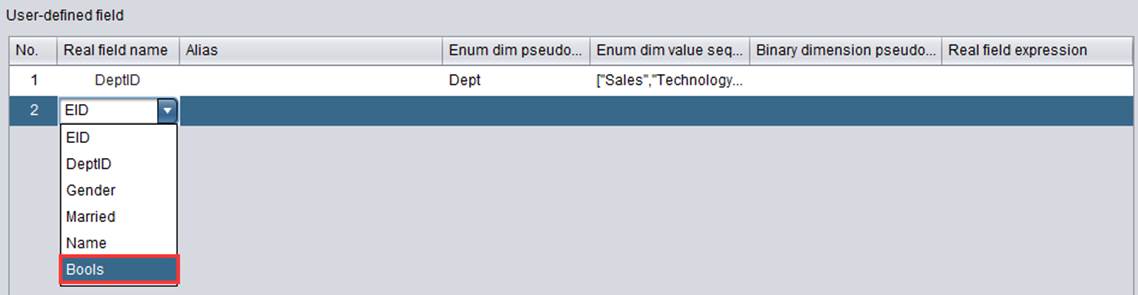
双击Binary dimension pseudo field :
【Binary dimension pseudo field】:设置二值维度伪字段名,最多可以存储32个二值字段。定义时按照真字段中从低位到高位对应的字段来设置,各个字段的值都是布尔值false或者true。
设置Bools的二值维度伪字段名:

也就是IfMarried和IfLady的值为true或者false。
点击【OK】后,特殊字段定义如下图:

虚表字段有变动,将字段修改同步到DQL表后再做查询。DQL查询结果如下:
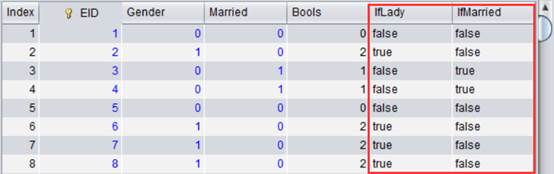
由上图可看出Married/Gender和IfMarried/IfLady的对照关系。IfMarried和IfLady字段值为布尔值。
过滤条件中的IfLady会被自动转换为 Bools 字段的第 2 位,再用来过滤物理表。
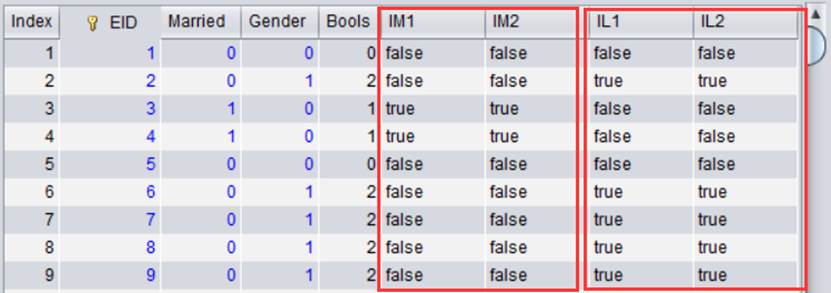
我们可以在别名型伪字段列表处设置多个值,表示IfMarried的别名为IM1和IM2,IfLady的别名为IL1和IL2。

【Alias】:设置别名型伪字段列表。当值为字符串时,表示给二值维度伪字段名或真字段的表达式起别名,可以设置多个值,表示每个伪字段有多个别名;当值为表达式时,返回当前表达式的计算结果,比如在下面别名型伪字段章节中的使用。
DQL查询结果如下:
冗余字段
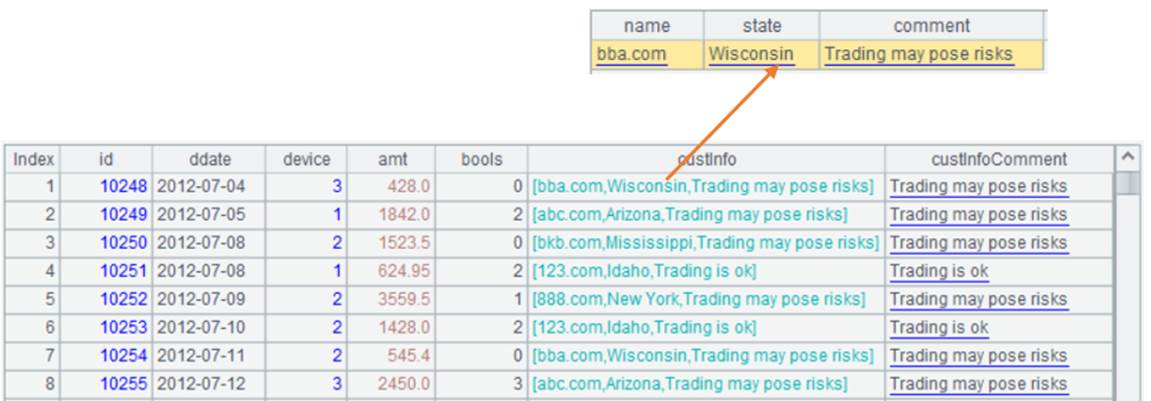
实际业务中为了优化查询性能,有的表会有冗余字段。比如Details.ctx的一个记录字段custInfo,存储当前交易的客户信息comment。如果要筛选custInfo.comment的数据,需要读取整个custInfo的内容,即使 custInfo 的其他字段不参与计算,也要被全部读入。为了减少读取的数据,物理表增加一个冗余字段custInfoComment,用来存放custInfo.comment的值。
Details.ctx表内容如下:
而冗余字段custInfoComment和记录字段custInfo.comment的关系需要特殊说明,针对此种情况,虚表提供冗余字段机制,可以定义一个冗余字段对应的计算式exp,如果计算表达式中出现 exp,会自动用冗余字段代替。
新建元数据文件test.glmd,点击【增加虚表】按钮![]() ,添加一个虚表,选择pseudo文件夹中的Details.ctx:
,添加一个虚表,选择pseudo文件夹中的Details.ctx:
点击![]() 按钮,在User-defined field中增加一个特殊字段。Real
field name下拉列表中选择custInfoComment字段:
按钮,在User-defined field中增加一个特殊字段。Real
field name下拉列表中选择custInfoComment字段:
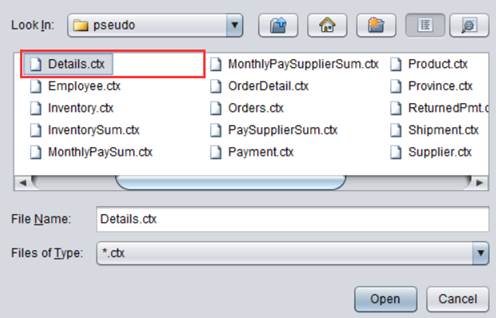
编辑Real field expression为custInfo.comment:
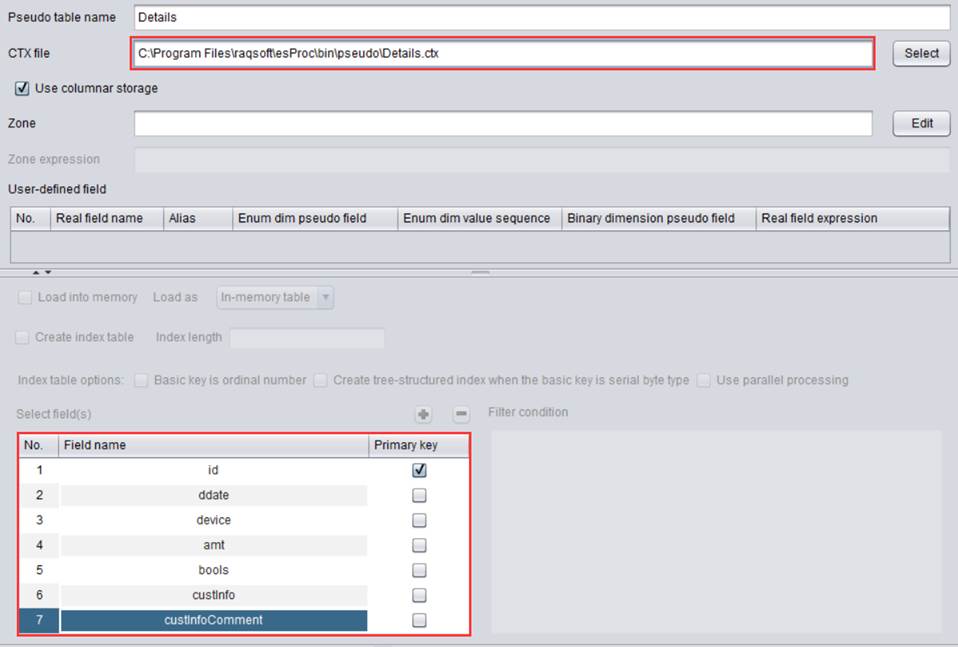
【Real field expression】:设置真字段的表达式。
至此,虚表定义就完成了。接下来将虚表定义导出到SPL文件。
在菜单栏中点击File - Export pseudo tables to SPL file,将虚表定义导出到SPL文件,用集算器打开.splx文件:
|
|
A |
B |
|
1 |
=[{name:"Details",file:"pseudo/Details.ctx", zone:null, column:[{name:"custInfoComment", alias:null, enum:null, list:null, exp:"custInfo.comment", bits:null, date:null}]}] |
=pseudo@v(A1) |
点击【执行】按钮,执行SPL脚本,可查看A1计算结果,即虚表定义结果,双击column查看冗余字段的定义。
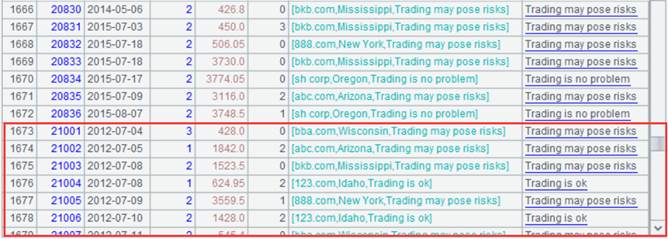
使用冗余字段过滤custInfo.comment 字符串包含 "risk" 子串的数据:
|
|
A |
B |
|
|
1 |
=[{name:"Details",file:"pseudo/Details.ctx", zone:null, column:[{name:"custInfoComment", alias:null, enum:null, list:null, exp:"custInfo.comment", bits:null, date:null}]}] |
=pseudo@v(A1) |
定义虚表。 |
|
2 |
=B1.select(pos(custInfo.comment,"risk")) |
|
|
|
3 |
=A2.import() |
|
|
A3结果:
A1中定义了一个计算式 exp:"custInfo.comment"和对应的真实字段 custInfoComment。
当A2过滤条件中出现计算式exp时,并不会取出 custInfo 的记录再取其中的字段,而是被替换成真实字段 custInfoComment,用冗余字段的值完成接下来的计算。
如果想对组表进行追加、修改、删除数据,直接修改SPL脚本即可。
例如:将details_new.btx中的数据追加到Details.ctx。details_new.btx中有字段 custInfo,没有custInfoComment。details_new.btx数据如下:

SPL 脚本如下:
|
|
A |
B |
|
|
1 |
=[{name:"Details",file:"pseudo/Details.ctx", zone:null, column:[{name:"custInfoComment", alias:null, enum:null, list:null, exp:"custInfo.comment", bits:null, date:null}]}] |
=pseudo@v(A1) |
定义虚表。 |
|
2 |
=file("pseudo/details_new.btx").cursor@b(id,ddate,device,amt,bools,custInfo) |
|
将数据读成游标。 |
|
3 |
=B1.append(A2) |
|
追加数据。 |
执行脚本,系统会自动转换生成 custInfoComment。追加数据后的Details.ctx:
别名型伪字段
实际应用中,真字段在不同场景下可能承载不同业务含义,在虚表特殊字段定义中,可通过字段别名明确其具体业务含义。
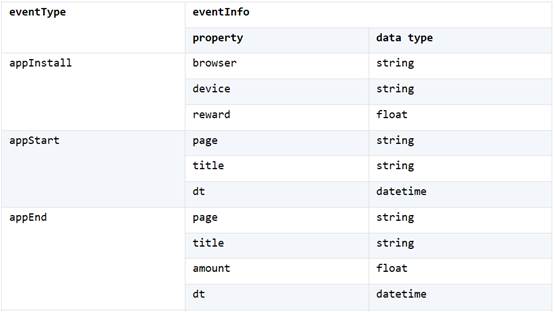
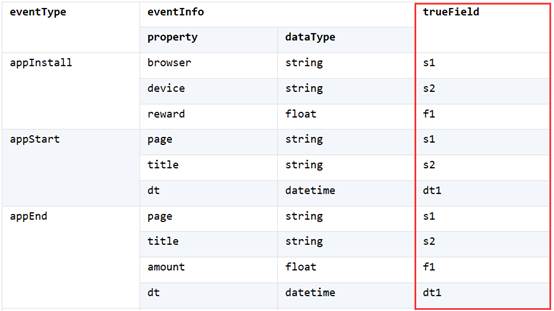
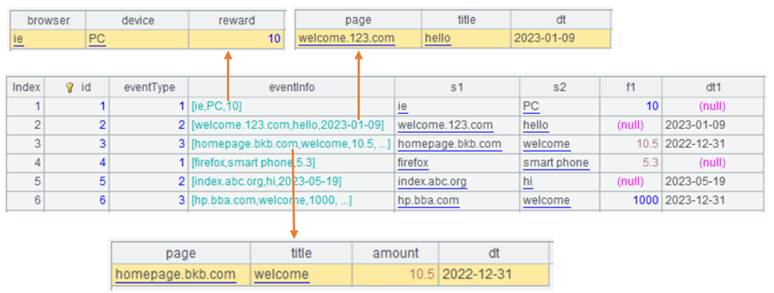
比如电商系统事件表 Events.ctx,表中每一行是一个事件。每个事件都要存储事件类型 eventType 以及这类事件对应的属性信息 eventInfo。eventInfo 是一个记录字段,又包含多个字段,用来存储多个属性。

需要注意的是:不同类型的事件有不同的属性,相同类型的事件的属性相同。也就是说,eventType 字段值决定了 eventInfo 这条记录的字段个数、名称、数据类型。
eventType 和 eventInfo 中的各属性对照关系:

从表中可以看到,事件类型 appInstall 对应三个属性,appEnd 则对应完全不同的四个属性。由于事件类型很多,如果每个属性都存一个字段,就会让物理表有太多的字段。其实每种类型事件的属性个数并不会太多。
实际上,一个事件只能属于一个事件类型。假如一个事件属于 appInstall 类型,有 browser 属性,那么它就不可能有 appStart 类型的 page 属性。同时,这两个属性又都是字符串,我们可以用一个真字段 s1 来存储这两个属性。
以此类推,可以将同样数据类型的属性都合并起来,如下图:

如图所示,我们用真字段 s1 存储三类事件的三个字符串属性 browser、page 和 page。其他真字段 s2、f1、dt1 和 s1 类似。总体来看只需要 s1、s2、f1、dt1 四个字段就可以存储图上出现的所有属性。
这样,物理表的结构如下图:
物理表数据如下图:

虽然这样的物理表字段总数少很多,但是字段名看不出业务含义,不太方便使用。查询时还要根据 eventType 解释不同字段的业务含义,也增加了复杂度。
这种情况可以利用虚表的字段别名和计算式 exp 配合使用。虚表为每个真字段配置多个有业务含义的别名。
第一步:新建元数据文件test.glmd,点击【增加虚表】按钮![]() ,添加一个虚表,选择pseudo文件夹中的Events.ctx。
,添加一个虚表,选择pseudo文件夹中的Events.ctx。
此时Pseudo table name自动读取文件名:
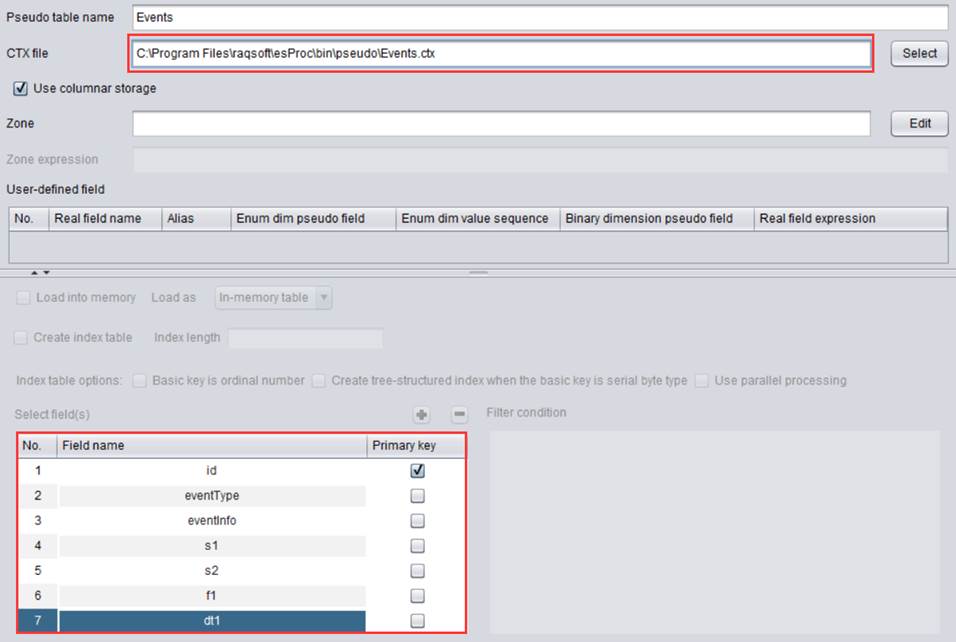
第二步:点击![]() 按钮,在User-defined field中增加一个特殊字段。Real
field name下拉列表中选择eventType字段:
按钮,在User-defined field中增加一个特殊字段。Real
field name下拉列表中选择eventType字段:

编辑Enum dim pseudo field为eventTypeString
双击Enum dim value sequence。
设置eventType对应的枚举值,从1开始,按位置对应,对应的编号转换为对应的值。
即eventType字段值1-3分别对应:["appInstall","appStart","appEnd"]
第三步:点击![]() 按钮,在User-defined field中增加第二个特殊字段。Real
field name下拉列表中选择s1字段:
按钮,在User-defined field中增加第二个特殊字段。Real
field name下拉列表中选择s1字段:
双击Alias
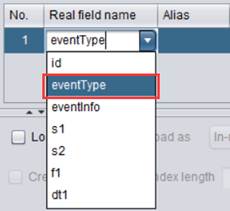
在别名型伪字段列表处设置多个值:["browser","appStart_page","appEnd_page"]
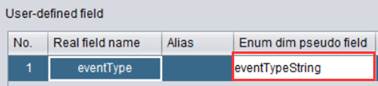
编辑Real field expression为case(eventType,1:eventInfo.browser,2:eventInfo.page,3:eventInfo.page),根据eventType的值返回eventInfo中对应的字段。

Alias列表按顺序分别对应Real field expression的三种情况,表示给真字段的表达式起别名。
第四步:按照第三步,在User-defined field中再增加三个特殊字:

现在虚表定义就完成了,接下来我们将虚表定义导出到SPL文件。
在菜单栏中点击File - Export pseudo tables to SPL file,将虚表定义导出到SPL文件。用集算器打开.splx文件:
|
|
A |
B |
|
1 |
=[{name:"Events",file:" pseudo/Events.ctx", zone:null, column:[{name:"eventType", alias:null, enum:"eventTypeString", list:["appInstall","appStart","appEnd"], exp:null, bits:null, date:null}, {name:"s1", alias:["browser","appStart_page","appEnd_page"], enum:null, list:null, exp:"case(eventType,1:eventInfo.browser,2:eventInfo.page,3:eventInfo.page)", bits:null, date:null}, {name:"s2", alias:["device","appStart_title","appEnd_title"], enum:null, list:null, exp:"case(eventType,1:eventInfo.device,2:eventInfo.title,3:eventInfo.title)", bits:null, date:null}, {name:"f1", alias:["reward","amount"], enum:null, list:null, exp:"case(eventType,1:eventInfo.reward,3:eventInfo.amount)", bits:null, date:null}, {name:"dt1", alias:["appStart_dt","appEnd_dt"], enum:null, list:null, exp:"case(eventType,2:eventInfo.dt,3:eventInfo.dt)", bits:null, date:null}]}] |
=pseudo@v(A1) |
点击【执行】按钮,执行SPL脚本,可查看A1计算结果,即虚表定义结果,双击column查看特殊字段的定义。

数据过滤:
|
|
A |
B |
|
|
1 |
=[{name:"Events",file:" pseudo/Events.ctx", zone:null, column:[{name:"eventType", alias:null, enum:"eventTypeString", list:["appInstall","appStart","appEnd"], exp:null, bits:null, date:null}, {name:"s1", alias:["browser","appStart_page","appEnd_page"], enum:null, list:null, exp:"case(eventType,1:eventInfo.browser,2:eventInfo.page,3:eventInfo.page)", bits:null, date:null}, {name:"s2", alias:["device","appStart_title","appEnd_title"], enum:null, list:null, exp:"case(eventType,1:eventInfo.device,2:eventInfo.title,3:eventInfo.title)", bits:null, date:null}, {name:"f1", alias:["reward","amount"], enum:null, list:null, exp:"case(eventType,1:eventInfo.reward,3:eventInfo.amount)", bits:null, date:null}, {name:"dt1", alias:["appStart_dt","appEnd_dt"], enum:null, list:null, exp:"case(eventType,2:eventInfo.dt,3:eventInfo.dt)", bits:null, date:null}]}] |
=pseudo@v(A1) |
定义虚表。 |
|
2 |
=B1.select(eventTypeString=="appInstall" && browser=="firefox") |
|
|
|
3 |
=A2.import(id,eventTypeString,browser,reward) |
|
取出过滤结果。 |
A3结果:
A2过滤条件中出现了字段别名,SPL 并不会取出 eventInfo 的记录再取其中的字段,而是自动替换成真实字段 s1,用冗余字段的值完成后续计算。
如果想对组表进行追加、修改、删除数据,直接修改SPL脚本即可。
例如:将events_new.btx中的数据追加到Events.ctx。events_new.btx 中有字段 eventTypeString和eventInfo。events_new.btx数据如下:
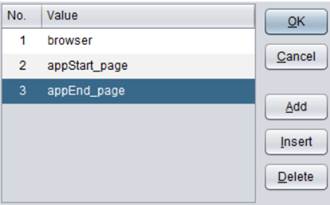
SPL 脚本如下:
|
|
A |
B |
|
|
1 |
=[{name:"Events",file:" pseudo/Events.ctx", zone:null, column:[{name:"eventType", alias:null, enum:"eventTypeString", list:["appInstall","appStart","appEnd"], exp:null, bits:null, date:null}, {name:"s1", alias:["browser","appStart_page","appEnd_page"], enum:null, list:null, exp:"case(eventType,1:eventInfo.browser,2:eventInfo.page,3:eventInfo.page)", bits:null, date:null}, {name:"s2", alias:["device","appStart_title","appEnd_title"], enum:null, list:null, exp:"case(eventType,1:eventInfo.device,2:eventInfo.title,3:eventInfo.title)", bits:null, date:null}, {name:"f1", alias:["reward","amount"], enum:null, list:null, exp:"case(eventType,1:eventInfo.reward,3:eventInfo.amount)", bits:null, date:null}, {name:"dt1", alias:["appStart_dt","appEnd_dt"], enum:null, list:null, exp:"case(eventType,2:eventInfo.dt,3:eventInfo.dt)", bits:null, date:null}]}] |
=pseudo@v(A1) |
定义虚表。 |
|
2 |
=file("pseudo/events_new.btx").cursor@b(id,eventTypeString,eventInfo) |
|
将数据读成游标。 |
|
3 |
=B1.append(A2) |
|
追加数据。 |
执行脚本,系统会根据eventTypeString,eventInfo自动生成 s1、f1 等。追加数据后的Events.ctx:

日期转换型伪字段
在实际的业务数据表中,日期相关字段的值不一定是直观的日期串,还有一种常见存储形式是以1970-01-01为基准日期计算得出的天数。
比如emdate.ctx表中的Birdays字段,就是以这种天数格式存储的,该表的原始数据内容如下:

如果想要把这类天数格式的字段值,转换成易读的标准日期串,则可以通过给虚表增加日期转换型伪字段的方式来实现,具体操作如下:
新建元数据文件t4.glmd,点击【增加虚表】按钮![]() ,添加一个虚表,选择上面的emdate.ctx文件,点击
,添加一个虚表,选择上面的emdate.ctx文件,点击![]() 按钮,在User–defined field中再增加一个特殊字段。Real field name下拉列表中选择Birdays字段,在【Date transfer field name】中配置日期转换型伪字段名为Bdate:
按钮,在User–defined field中再增加一个特殊字段。Real field name下拉列表中选择Birdays字段,在【Date transfer field name】中配置日期转换型伪字段名为Bdate:
配置完成后,将虚表转为DQL表,此时查询表数据,Bdate列便是转换后的日期串,内容如下: