导出为 SPLX 文件
ETL中定义的数据处理可通过SPL脚本的形式保存到SPLX文件中,执行SPL脚本后,根据导出配置生成数据文件。
点击工具菜单,有两种方式生成SPLX文件方式:
1, 生成SPLX文件,通常用于获取数据表的全量数据,然后根据导出设置写出到数据文件中;
2, 生成增量SPLX文件,通常用于获取数据表的增量数据,然后将增量数据与源文件数据的和集写入到新的数据文件中。

生成 SPLX 文件
在ETL界面中点击工具 – 生成SPLX文件,保存为EmpForETL.splx文件,生成脚本内容如下:
|
|
A |
|
1 |
=connect("demo") |
|
2 |
="D:\\file\\ETL\\" |
|
3 |
=A1.query("SELECT Distinct GENDER FROM EMPLOYEE") |
|
4 |
=A3.(GENDER).new(#:gender_id,~:gender).keys@i(gender) |
|
5 |
=file(A2+"EMPLOYEE_GENDER.btx").export@b(A4) |
|
6 |
=file(A2+"department.txt").import@t(DEPT,MANAGER;," ") |
|
7 |
=A6.keys@i(DEPT) |
|
8 |
=file(A2+"department.btx").export@b(A7) |
|
9 |
=A1.cursor("SELECT EID,NAME,GENDER,BIRTHDAY,DEPT,SALARY, FAMILY.EID AS FAMILY_EID,FAMILY.NAME AS FAMILY_NAME,RELATION,FAMILY.GENDER AS FAMILY_GENDER,AGE FROM EMPLOYEE LEFT JOIN FAMILY ON EMPLOYEE.EID=FAMILY.EID WHERE EID<?",arg1) |
|
10 |
=A9.sortx(EID).new(#@:id,EID,NAME,A4.pfind(GENDER):GENDER,BIRTHDAY,A7.pfind(DEPT):DEPT,SALARY, age(BIRTHDAY):EMP_AGE,FAMILY_EID,FAMILY_NAME,RELATION,FAMILY_GENDER,AGE) |
|
11 |
=file(A2+"EMPLOYEE.ctx").create@yp(#id,EID,NAME,GENDER,BIRTHDAY,DEPT,SALARY,EMP_AGE, FAMILY_EID,FAMILY_NAME,RELATION,FAMILY_GENDER,AGE).append(A10).close() |
|
12 |
=A1.close() |
在IDE中打开脚本文件,设置arg1参数值为51,即检索出EID值小于51的数据,执行脚本后,D:/file/ETL目录下分别生成文件EMPLOYEE.ctx、EMPLOYEE_DEPT.btx、gender.btx。
由源表EMPLOYEE导出的EMPLOYEE.ctx文件内容如下,组表中包含了EMPLOYEE表与FAMILY表关联后的字段,id列值为数据行的序号,GENDER列值为维表gender中的gid值 ,DEPT列为序号化表EMPLOYEE_DEPT中的deptID值,EMP_AGE列为导出设置中增加的新字段 :

由序号化枚举列配置生成的EMPLOYEE_DEPT.btx文件内容如下,dept列为EMPLOYEE表中的DEPT值:

由文本文件gender.txt作为数据源导出的gender.btx内容如下:

生成增量 SPLX 文件
在实际业务场景中,数据表的数据往往处于持续变化或增长的状态。针对增量数据的采集需求,ETL 工具提供了【生成增量 SPLX 文件】功能,该功能可通过检索条件筛选出指定数据,再与源数据文件“源表.xxx” 中的数据进行合并,最终生成名为 “源表_New.xxx” 的新数据文件。
仍以EMPLOYEE表为例,在上面的章节中,取到了EID<51的数据写入到了数据文件EMPLOYEE.ctx中,假如一段时间后数据表中记录有所增加,EID增加到了100,那么在这种情况下,若要将新增数据更新到数据文件,无需重复读取之前已提取过的数据,此时可通过增量更新的方式来实现,操作如下:
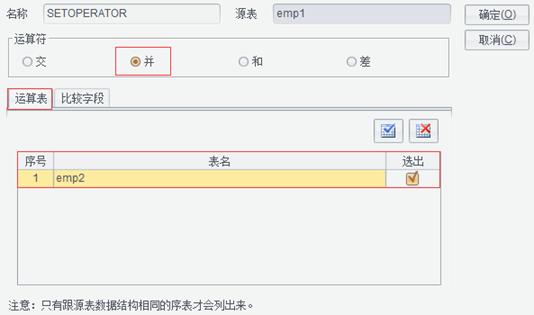
修改T1.etl文件,设置arg1值为51,增加参数arg2并设置值为100:
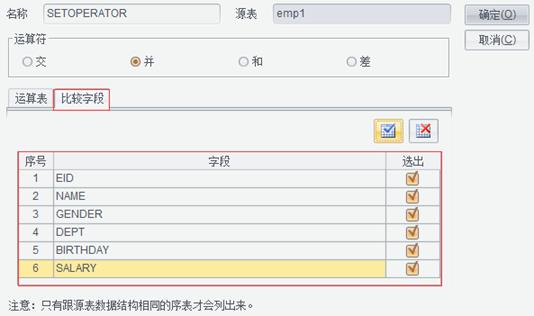
然后在EMPLOYEE表中设置检索条件:
设置完成后,点击工具 - 生成增量SPLX文件 ,保存为EmpForETL_New.splx文件,生成的脚本文件内容如下:
|
|
A |
|
1 |
=connect("demo") |
|
2 |
="D:\\file\\ETL\\" |
|
3 |
=A1.query("SELECT Distinct GENDER FROM EMPLOYEE") |
|
4 |
=T1=file(A2+"EMPLOYEE_GENDER.btx").import@b().keys@i(gender) |
|
5 |
=T2=A3.(GENDER) |
|
6 |
=T3=T2.select(!T1.pfind(~)).new(#+T1.len():gender_id,~:gender) |
|
7 |
=(T1 | T3).derive().keys@i(gender) |
|
8 |
=file(A2+"EMPLOYEE_GENDER_New.btx").export@b(A7) |
|
9 |
=T1=file(A2+"department.btx").import@b().keys@i(DEPT) |
|
10 |
=file(A2+"department.txt").import@t(DEPT,MANAGER;," ") |
|
11 |
=A10.keys@i(DEPT) |
|
12 |
=T2=A11 |
|
13 |
=T3=T2.select(!T1.pfind(DEPT)) |
|
14 |
=(T1 | T3).derive().keys@i(DEPT) |
|
15 |
=file(A2+"department_New.btx").export@b(A14) |
|
16 |
=T1=file(A2+"EMPLOYEE.ctx") |
|
17 |
=T1.open().cursor().skip() |
|
18 |
=A1.cursor("SELECT EID,NAME,GENDER,BIRTHDAY,DEPT,SALARY, FAMILY.EID AS FAMILY_EID,FAMILY.NAME AS FAMILY_NAME,RELATION,FAMILY.GENDER AS FAMILY_GENDER,AGE FROM EMPLOYEE LEFT JOIN FAMILY ON EMPLOYEE.EID=FAMILY.EID WHERE EID between ? and ?",arg1,arg2) |
|
19 |
=A18.sortx(EID).new(#@+A17:id,EID,NAME,A7.pfind(GENDER):GENDER,BIRTHDAY,A14.pfind(DEPT):DEPT,SALARY, age(BIRTHDAY):EMP_AGE,FAMILY_EID,FAMILY_NAME,RELATION,FAMILY_GENDER,AGE) |
|
20 |
=movefile@y(A2+"EMPLOYEE_New.ctx") |
|
21 |
=T1.reset(file(A2+"EMPLOYEE_New.ctx");A19) |
|
22 |
=A1.close() |
在IDE中执行上述增量脚本文件,生成新的数据文件内容如下:
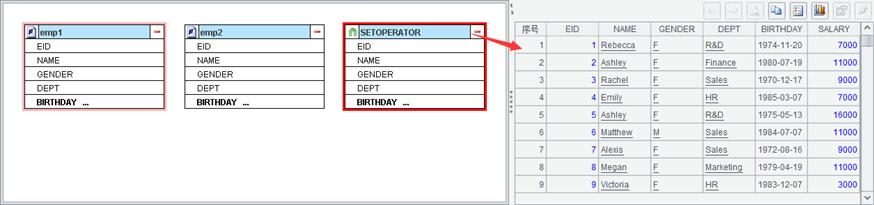
EMPLOYEE_New.ctx数据内容如下,结果集为EMPLOYEE.ctx数据(EID<51)与增量数据(EID>=51&&EID<=100)的和集:
执行增量SPLX脚本时,序号化表数据文件也会按规则生成新的数据文件,EMPLOYEE增量数据中DEPT列新增了枚举值Technology,所以序号化枚举列中也会相应的获取到增量数据,生成的EMPLOYEE_DEPT_New.btx内容如下,结果集为EMPLOYEE_DEPT.btx与增量数据的和集:
genter.txt表没有变化,所以gender_New.btx内容与gender.btx内容相同,没有变化: