配置变量
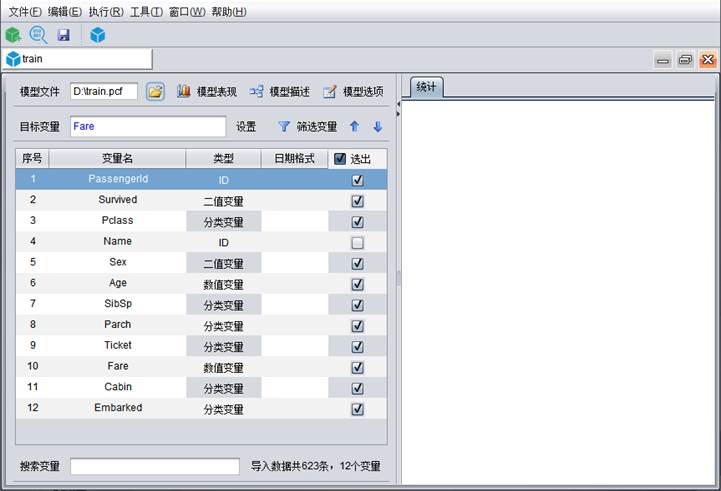
导入数据后,需要进行变量的配置,下面我们以导入train.mtx为例,介绍配置变量操作。
搜索变量
在上图中可以看到,数据导入之后,设计器底部出现搜索变量的功能,并且搜索框后面会显示当前导入的数据条数及变量个数;当变量数较多时,想要快速定位某个变量,可以使用搜索变量的功能。
衍生变量
衍生变量是通过对原始变量数据进行加工,生成更加有意义的新的变量,更加适合后续的数据建模。
在菜单栏中点击编辑 - 增加衍生变量,在弹出窗口中配置衍生变量名称、衍生变量表达式,点击确定即可增加衍生变量。衍生变量表达式中可以引用已存在的变量及产品中的函数,点击函数名称可以查看对应函数说明。
例如,增加衍生变量Sex_b,衍生变量Sex_b的值定义为变量Sex值的首字母,那么写法如下:
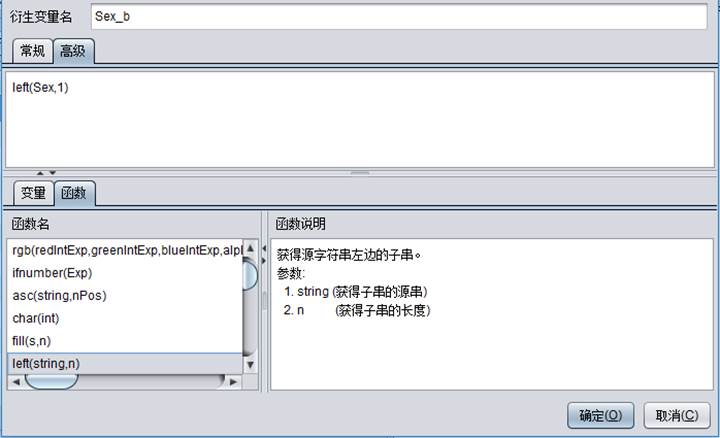
增加的衍生变量与普通变量用法一致。
在【常规】标签中可以看到几种常见的变量表达式设置:比率、时间间隔、交互、转换、分箱。根据常见的变量表达式可以帮助用户快速定义衍生变量。
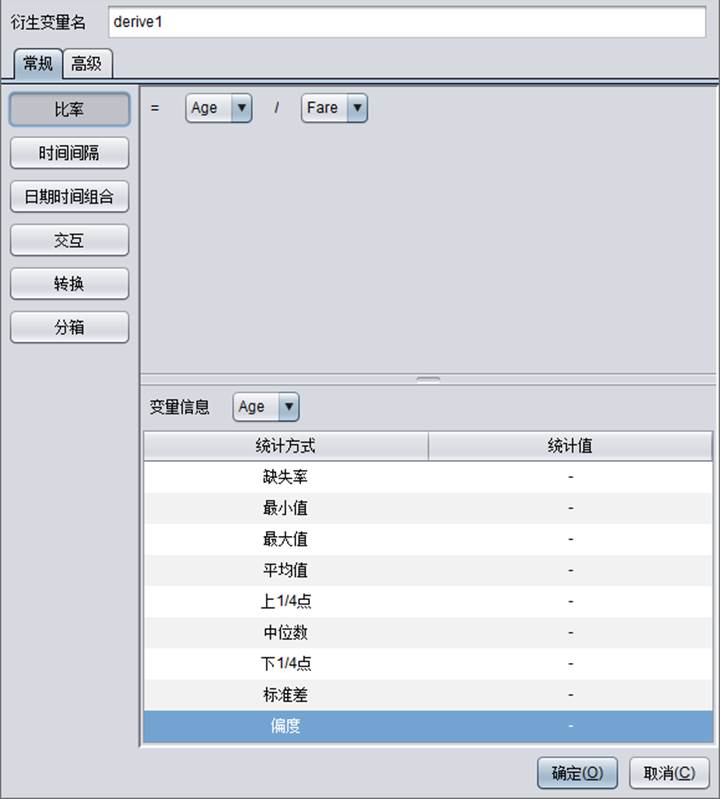
(1)比率:ratio = ![]()
变量x1和x2的下拉列表中只显示数值变量和计数变量,生成的结果为数值变量。
(2)时间间隔:interval = x1-x2
变量x1和x2的下拉列表中只显示时间日期类型的变量和自定义日期时间,生成的结果为数值变量。
时间间隔单位包括:毫秒,秒,分,时,日,周,季度,月,年。
(3)日期时间组合:生成日期、时间或日期时间的变量。
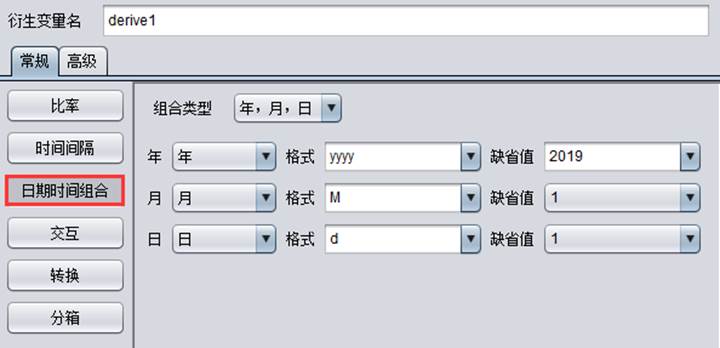
组合类型包括:
年,月,日(即生成日期变量)

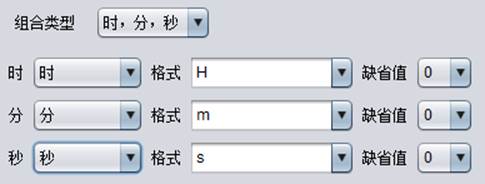
时,分,秒(即生成时间变量)
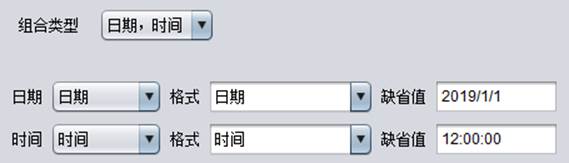
日期,时间(即生成日期时间变量)。
格式:设置符合当前选中字段的数据格式。
注意:
(1)当组合类型是“年,月,日”类型时,如果月选择格式“MMM”时,需要在导入数据时先修改“区域和语言”为英文。![]()
(2)当组合类型是“日期,时间”类型时,如果日期选择默认格式“日期”时,则日期缺省值的格式应该和配置里的默认格式一致;时间同理。如果日期选择格式“yyyyMMdd”时,则日期缺省值的格式应该和当前设置的格式一致;时间同理。
(4)交互:两个同为数值变量或2个同为分类变量可以交互,一个数值变量和一个分类变量不能交互。
两个数值变量交互:interactive = ![]()
两个分类变量交互:interactive =![]()
例如:x1=[0,1,1,1,0,0,1];x2=[0,1,2,3,2,1,1],计算结果为:
[(0,0), (1,1), (1,2), (1,3), (0,2), (0,1), (1,1)],以字符串的形式呈现结果。
变量x1和x2的下拉列表中只显示数值变量、计数变量和分类变量。当变量x1选择数值变量或计数变量后,变量x2只可以选择数值变量或计数变量;当变量x1选择分类变量后,变量x2只可以选择分类变量。
数值变量交互时,结果为数值变量;分类变量交互时,结果为分类变量。
(5)转换:支持的函数有对数、正切、反正切、双曲正切。当选择对数时,底数可以是e、2或10。
正切:tangent = tan(x)
反正切:arc tangent = arctan(x)
双曲正切:hyperbolic tangent = 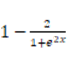
变量x的下拉列表中只显示数值变量和计数变量,生成的结果为数值变量。
(6)分箱:
变量x的下拉列表中只显示数值变量和计数变量,生成的结果为二值变量、分类变量或数值变量,根据实际分箱结果判定。
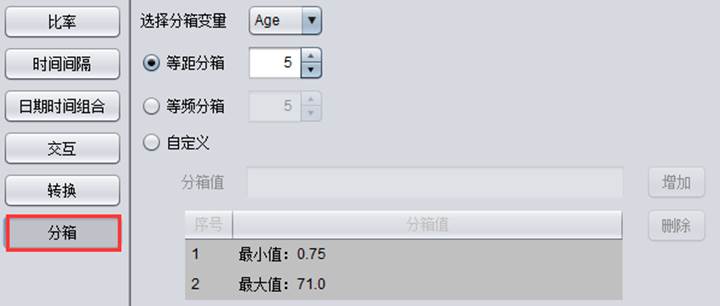
等距分箱和等频分箱的分箱个数介于2-100之间。
自定义分箱:在分享值的输入框中一个一个输入介于最大值与最小值之间的分箱值,点击“增加”按钮即可。
变量统计
变量统计的功能是计算出各个变量的具体信息。可以单个变量统计,也可以直接统计全部变量。操作步骤如下:
选中要统计的变量,在菜单栏【执行】中,点击【变量统计】或【统计全部变量】。
例如选择统计全部变量:
当窗口中输出“变量统计完成”时表示统计完毕。
建模所用的变量类型共有8种,分别为:数值变量、单值变量、二值变量、计数变量、分类变量、ID、日期、长文本。
其中ID类型变量、长文本类型变量不作统计;分类变量统计其缺失率与势,并通过统计出的数据生成饼图,缺失率表示该变量值缺失的记录数占总记录数的百分比,势表示该变量唯一值个数。
例如分类变量Embarked,该变量有四类值,分别为S、C、Q、缺失值。那么变量统计结果如下:
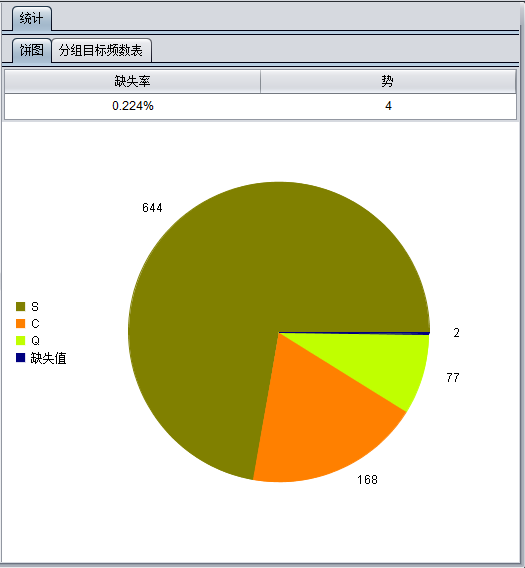
单值变量及二值变量与分类变量类似,统计变量的缺失率与势,单值变量的势固定为1,二值变量的势固定为2。
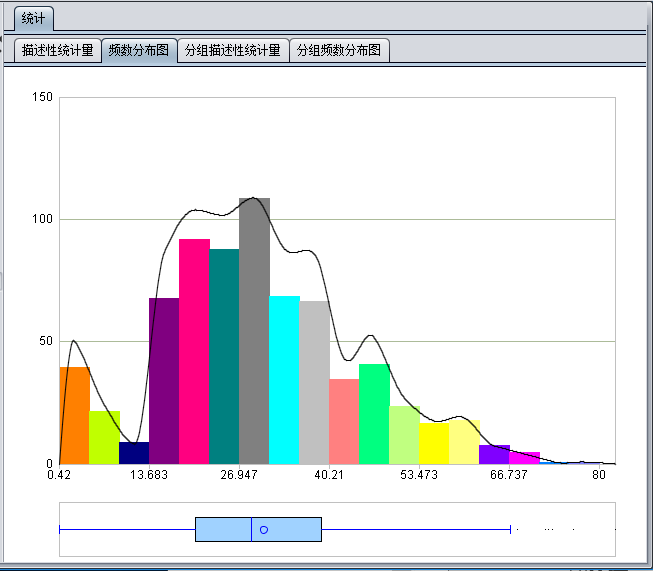
计数变量与数值变量统计形式一样,统计的数据项中包括描述性统计变量、频数分布图、分组描述性统计量、分组频率分布图。例如数值变量Age的统计结果:

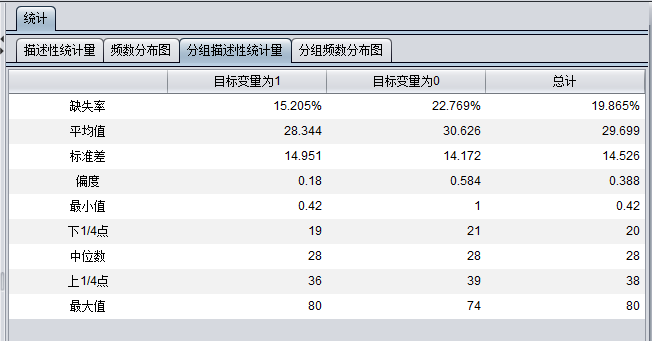

日期类型的变量,统计的数据项包括描述性统计变量、频数分布图、分组描述性统计量、分组频率分布图。但是一般只有在描述性统计变量和分组描述性统计量选项中有体现,如下图所示:


筛选变量
变量筛选分为“根据重要度”和“根据变量类型”两种方式。两种筛选方式通用的配置项为:【仅在已选字段中筛选】,该项为未勾选状态时,在所有变量中筛选,勾选状态则在已经选中的字段中进行筛选。
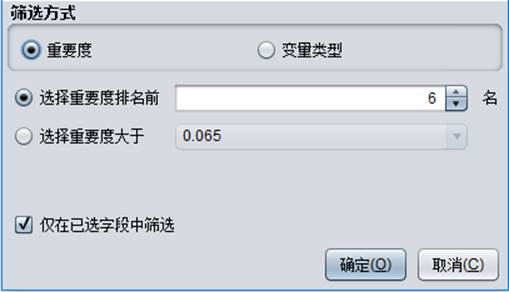
重要度
执行建模之后,变量面板中才会显示每个变量的重要度;重要度方式筛选变量是在第一次建模之后,根据模型返回的变量重要度,重新筛选变量;ID类型的变量重要度为0,目标变量不计算重要度,用户可以根据重要度的排名选择前几名的变量,也可以选择重要度大于某个值的变量。第一次建模前重要度方式为灰色状态无法选择。
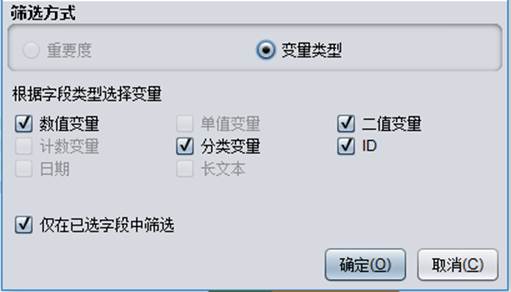
变量类型
变量类型方式筛选,则根据字段的类型选择变量,灰色状态的类型表示导入的数据中不包含该类型的变量。
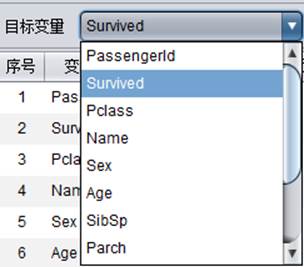
目标变量
目标变量即建模后作为分析目标的变量,目标变量也可以理解为预测字段。下拉列表中包含导入的所有变量名称,下拉后选择即可。需要注意的是目标变量仅支持二值变量及数值类型变量。
本案例中将二值变量Survived作为目标变量: